I dropped 80-something documents into my project repo a few months ago. Research notes, paper summaries, meeting transcripts, half-written drafts. Every time I open Claude Code and ask it something, it reads them. Different combinations, different orderings, but the same files. Same synthesis. Same connections being rediscovered, on my dime.
Last week I asked a question I'm pretty sure I'd already asked two weeks earlier. The answer was good. The answer was also basically the same as last time. Two paid thinking sessions, ten minutes apart on the calendar, pretending to be independent.
That's around when Karpathy's llm-wiki gist hit my feed. 5000+ stars in a few days. The pitch — pre-compile knowledge once, then query the compiled version — landed on a problem I'd already started to feel.
What Claude Actually Does With My Docs
Worth saying out loud, because most people I talk to assume there's some kind of memory or index doing the work. There isn't. Not in Claude Code.
What auto-loads is CLAUDE.md. That's it. Everything else — the 80 notes, the docs folder, the example prompts — gets read on demand. The model decides which file to open. It opens it. It reads. It thinks. It answers. Then the context gets compacted and the next conversation starts fresh.
The Claude.ai Projects UI is a different beast. Past a certain context limit, Projects silently switches into RAG mode — a project knowledge search tool that retrieves chunks from your uploads, expanding capacity by something like 10x. So the chat UI does retrieval. Claude Code does not.
Both share the same property, though: every synthesis is disposable. The model looks, connects dots, gives an answer, and the connection is gone. For five documents that's fine. For 80 it gets expensive. For the 200+ I'd have if I imported my whole research archive, it would be absurd.
Karpathy's Bet
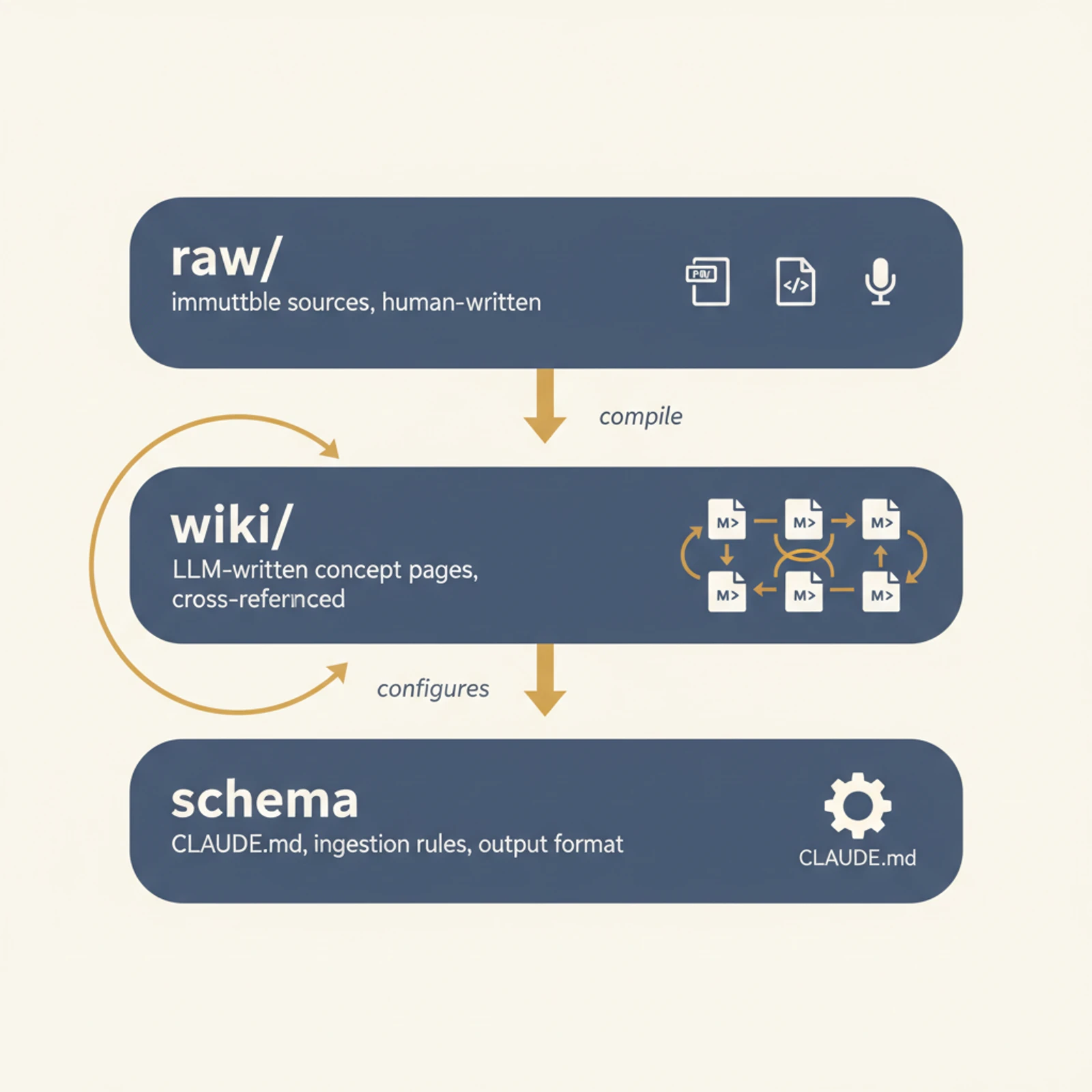
Three layers. That's the whole architecture.
raw/— your original sources. Papers, transcripts, articles, repo dumps. Immutable. Humans put things in.wiki/— markdown pages written by the LLM. One concept per file, cross-linked like a real wiki. LLM writes, humans read.schema— aCLAUDE.mdplus a few workflows, telling the LLM how to ingest new raw material into wiki pages and how to format answers. Humans configure once.
The slogan: pre-compile, then query.
The leap is small but real. RAG asks the model to do synthesis at query time, every time, from scratch — embed, retrieve, re-think. The wiki asks the model to do synthesis at write time, then queries just read what's already been written. Synthesis sediments into a file. The next session reads the file, not the originals.
Karpathy calls the wiki a "persistent, compounding artifact." That's the part that stuck with me. The 80 notes I have aren't a knowledge base. They're a pile that I'm asking Claude to re-discover the structure of, every conversation.
Where The Pattern Probably Works
A few weeks of reading critiques — Aaron Fulkerson's production write-up, the rohitg00 v2 gist, assorted blog posts — gave me a fairly clear shape of where this lives.
Probably good fit:
- Long-running personal or small-team research repos. Static-ish documents. The kind of thing where you accumulate notes for a year and ask "what did we think about X again?"
- Project-scoped knowledge. A single client engagement. A single product area. Bounded enough that the wiki doesn't sprawl.
- Things where you want the synthesis to be human-readable and editable. Markdown. Diff-able. Reviewable in git.
- Workflows already centered on Claude Code, Cursor, or Obsidian. The wiki is just files. Nothing exotic to host.
Probably bad fit:
- Real-time data. Stock prices, monitoring, support tickets, anything stale the moment it's compiled.
- Knowledge bases at company scale. Not because the model can't handle the volume — because once you cross some threshold of pages, nobody knows what the navigation looks like. Karpathy doesn't either. The gist explicitly punts on this.
- Regulated domains where every claim needs to point at the original source. v1 has no provenance. v2 added it, but it's bolted on.
- Multi-tenant scenarios. Markdown files don't have permissions.
For me the line is roughly: project-scoped works, full personal-document-graveyard does not. My consulting notes broken out by client would fit. A grand "everything I've ever read" wiki would be a maintenance hellhole within a year.
The Catches I Want To Front-Load
I'm convinced enough by the pattern to actually try it. I'm also convinced enough by the critiques not to walk in naive.
Hallucinations compound. This is the one that scared me. If the LLM writes something wrong into the wiki, the next session reads its own bad writing as if it were source. Errors don't get refuted at query time anymore — they get reinforced. RAG at least lets the model re-encounter the original passage and self-correct.
No provenance, by default. Karpathy's v1 doesn't include "this paragraph came from this source, with this confidence." You either bolt it on yourself, or you use the v2 gist, or you build it into your schema from day one.
Cold start is slow. RAG you can ship in an afternoon. A wiki you have to compile first, and that's LLM compute on every page, every cross-reference, every concept entity. For my 80 notes, probably an hour of compute. For someone with a thousand sources, this is a real cost line item.
Maintenance is the silent killer. Stale pages. Orphan pages nobody links to. Concept drift — the same idea ending up under three different names because three sessions wrote three different pages. None of this shows up in the demo. All of it shows up at month three.
What Aaron Fulkerson Actually Built
Probably the most useful thing I read. He extended Karpathy's pattern into a production system he calls Exo: 26 skills, 14 MCP servers, 8 hooks, an Obsidian vault as the wiki layer.
Two details I'm stealing.
The raw layer isn't files — it's MCP feeds. Gmail, Slack, HubSpot, Calendar, Apple Notes, Granola transcripts, WHOOP biometrics. Live data flows into the wiki on a cadence. That sidesteps the "wiki is stale" problem for anything that's actively pulled. Karpathy's gist treats raw as immutable archives. Fulkerson treats raw as a stream.
Hooks enforce behavior. Email safety gates that block sends without approval. A "TIL capture" hook that writes a wiki entry on every commit. MCP audit logs. The wiki doesn't drift because the hooks keep pruning, capturing, gating. This is the part that's missing from the pure pattern, and it's the part that turns a demo into something you can run for a year.
He's not running a toy. He's running it as his actual operating layer. That's a different proof than 5000 GitHub stars.
What I'm Going To Do
Concrete, because vague intentions don't ship.
I'm taking my long-running research notes — the project-scoped ones, not everything I own — and converting them into a three-layer structure. raw/ for the originals, untouched. wiki/ for LLM-compiled concept pages. A CLAUDE.md schema that says: "when ingesting a new raw doc, decide which existing wiki pages to update, write provenance lines for every claim, flag contradictions with existing pages."
Three things I'm doing differently from the v1 gist.
-
Provenance from day one. Every claim in a wiki page links back to the raw file and a line range. Not a nice-to-have. The whole compounding-error problem starts the moment you can't audit.
-
A weekly drift check. A scheduled task that asks the LLM to scan the wiki for orphan pages, contradictions, and concepts that should probably be merged. I'd rather catch drift on my schedule than discover it when an answer goes sideways.
-
Project-scoped, not personal-archive scoped. I'm not building an "everything I know" wiki. One repo, one bounded topic. If it works there, I'll fork the pattern. If it rots in two months, the failure is contained and the lesson is cheap.
I'm not betting that this replaces RAG or fixes everything. I'm betting that for a particular class of work — long-running, document-heavy, one-person-or-small-team — pre-computed synthesis beats running the same model over the same notes for the eighteenth time.
The model is getting cheaper every month. The synthesis I keep paying it to redo is not.
Karpathy's bet, basically: stop paying for the same thinking twice. Worth trying for a few weeks. I'll know if it actually compounds, or if I just built a slightly fancier filing cabinet.