Last night I sent a message to my AI assistant. Nothing. Tried again, different channel, still nothing. The OpenClaw gateway had gone dark.
I pulled up the logs expecting something mundane. What I found was the gateway had been dying and restarting for sixteen hours straight. Every time it came up, something killed it thirty seconds later.
At 3:31 AM the gateway got a SIGTERM and shut down cleanly. launchd did its job and restarted it. Normal. Except it kept dying. At 5 AM the auto-update script ran, update succeeded, nothing changed version-wise — but afterward the gateway's service entry silently disappeared from launchd. So when it died again, nothing brought it back.
I manually reloaded the service. Dead again thirty seconds later. Tried three more times, same pattern. Something was connecting to it via WebSocket, querying channels.status, then sending SIGTERM. Eventually the process tree showed this:
Update PID 99179 parent: 99060 (openclaw-gateway)The gateway was spawning its own update process, which was killing the gateway, which launchd was restarting, which was spawning another update process.
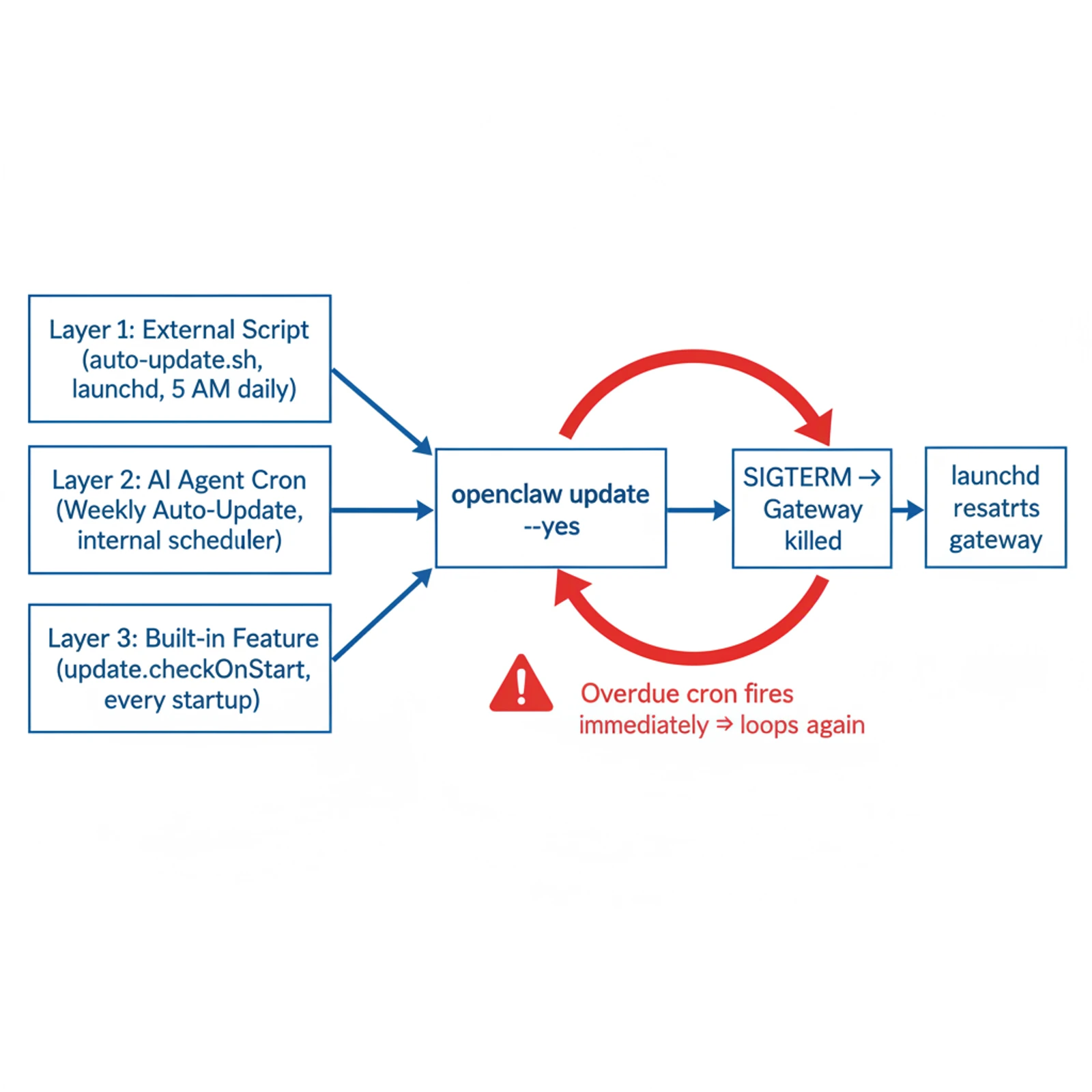
Once we had the full picture, it wasn't one thing — it was three things, each doing exactly what it was supposed to:
| What | Who set it up | When | |
|---|---|---|---|
| ① | auto-update.sh via launchd | Me | Daily, 5 AM |
| ② | "Weekly Auto-Update" cron | The AI agent | Weekly (or on startup if overdue) |
| ③ | update.checkOnStart | OpenClaw new version | Every gateway startup |
All three ran openclaw update --yes. All three issued SIGTERM to restart afterward.
Layer ① I set up myself months ago. Layer ③ shipped in a recent OpenClaw version with checkOnStart: true by default — I hadn't noticed. Layer ② I genuinely had no idea about. The AI agent created it.
OpenClaw agents can schedule their own tasks via openclaw cron create. At some point — probably when I said something vague like "keep the system up to date" — the agent created two cron jobs: OpenClaw Weekly Auto-Update (core+skills) and a retry variant. Completely reasonable from its perspective. It couldn't see auto-update.sh sitting on the filesystem. It checked its own cron list, found nothing, made one.
The part that turned a nuisance into a sixteen-hour outage was the catch-up behavior. OpenClaw marks overdue tasks and fires them immediately when the gateway comes back up. The gateway had been offline for hours. The moment it restarted, both cron jobs fired — SIGTERM, launchd restarts, cron fires again, loop.
Fix was three commands:
openclaw cron delete <id1>
openclaw cron delete <id2>
openclaw config set update.checkOnStart falseSingle update entry point. Been stable since.
What I keep thinking about isn't the bug itself. It's that the agent was right. I'd asked it to keep things updated, it found a way to do that, it did it. The problem is it had no visibility outside its own context — no way to know an OS-level script was already handling the same job.
This is a version of a problem that infrastructure engineers have dealt with for years: the gap between what your automation tool thinks the world looks like and what the world actually is. Terraform calls it state drift. You add a resource manually in the AWS console, Terraform doesn't know, and the next apply either overwrites it or produces a conflict. The solution there was to make infrastructure-as-code the single source of truth and stop touching things manually.
AI agents make this messier. The agent isn't just a tool you run — it's an actor that makes decisions and creates persistent state across sessions. It schedules tasks, writes configs, modifies files. Each of those actions is correct in isolation. But the agent's "world model" is bounded by what it can observe, and what it can observe is usually its own application layer. The OS layer — launchd, crontab, systemd, shell scripts — is mostly invisible to it.
A few directions that would actually help:
Cross-layer visibility tools. Before creating any scheduled task, an agent should be able to query: "what automation already exists on this machine that does something similar?" Right now there's no standard way to do this. An MCP server that unified launchctl list, crontab -l, and the agent's own cron list into a single queryable interface would have caught this immediately.
Declarative state for agent-managed automation. The same way Terraform has a state file, an agent-managed system should have a manifest of everything the agent has created — cron jobs, config changes, installed services. Human-readable, version-controlled, diffable. When the agent wants to create something new, it checks the manifest first. When a new software version introduces a built-in feature that overlaps with something in the manifest, there's at least a visible conflict to resolve.
Scope boundaries at setup time. When you install an AI agent that can manage your system, you should be able to say: "you own scheduling, the OS-level scripts are mine, don't touch those." Like IAM roles, but for agent capabilities. Not every agent platform supports this granularity yet, but it's the right model.
The practical thing I'm doing now is just running openclaw cron list occasionally. The agent will keep adding things as it solves problems, and some of those will outlive the conversation where they were created. It's manual, it doesn't scale, but it's what exists.
The harder version of this problem is that agents are going to get more capable, not less. The more they can do, the more invisible state they accumulate. Some platform is going to figure out a good answer to this — probably something that looks like a combination of audit logging and declarative ownership. Until then, incident reports that start with "I didn't know it was doing that" are going to be pretty common.