My company just ran an internal training on their new AI agent builder platform. The session was genuinely good — the platform is slick, the demos were compelling, and the vision of democratizing AI across the organization is inspiring. By the end, you could see it in people's eyes: "I could build this. I could automate my work."
And they can. That's the remarkable part. A proposal manager who's never written code can now configure an AI agent to draft client presentations, pulling from internal case studies and formatting everything to brand standards. A finance analyst can build an agent that answers budget questions by querying multiple data sources without writing SQL. The barrier to entry has collapsed from "hire a developer" to "describe what you want."
But as I walked out of the session, a few questions kept circulating. Who are these tools actually for? What use cases genuinely benefit from agent-based workflows versus traditional automation? How do we navigate security and governance when every business user can potentially spin up an autonomous AI? And where do developers fit into a world of low-code agent builders?
The marketing pitch is straightforward: AI agents for everyone. The reality is more nuanced.
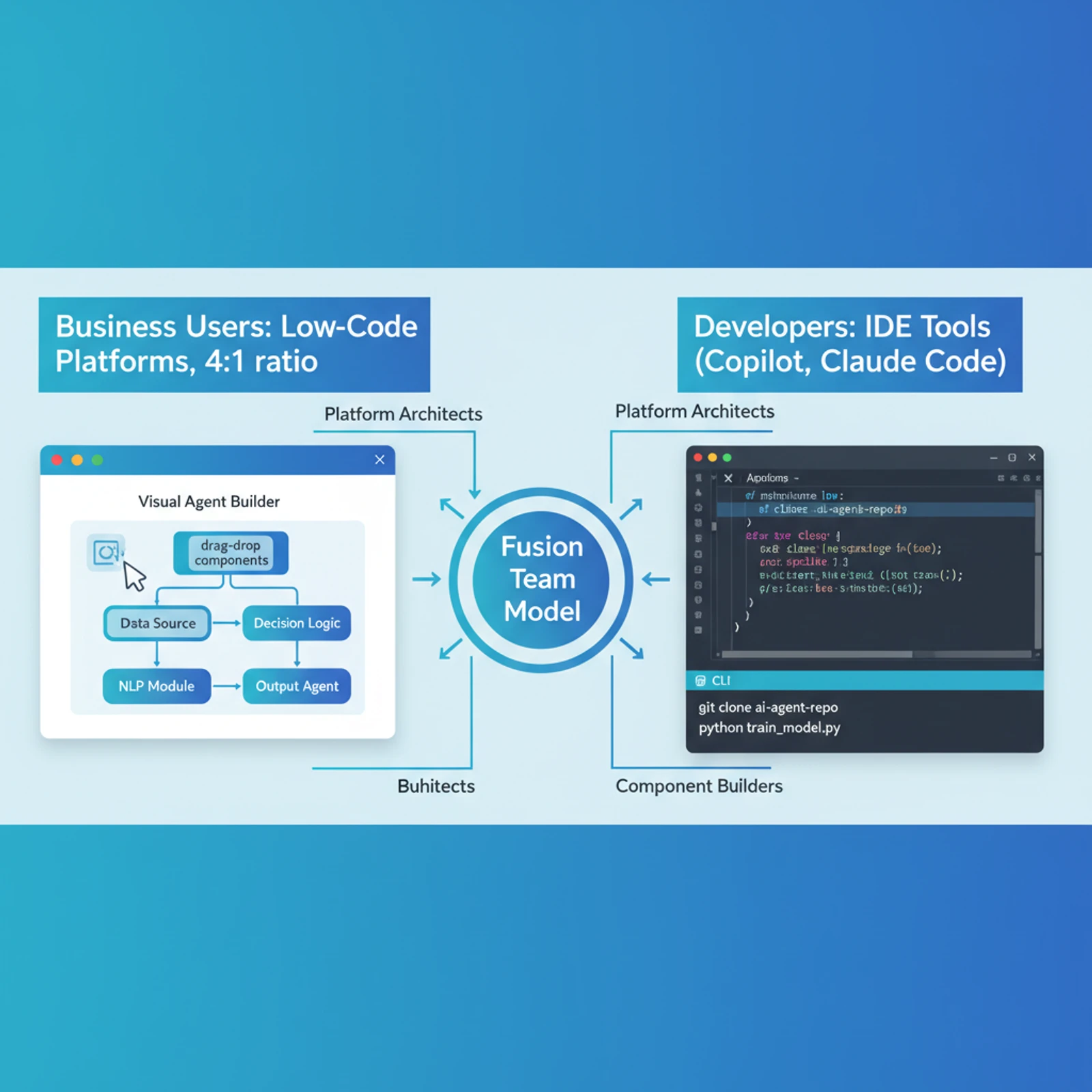
The Two-Track Reality: Business Users vs Developers
The agent builder platform my company introduced is impressive for what it is: a low-code, UI-driven environment where you configure system prompts, pick an LLM, connect to a knowledge base, and enable pre-built tools. It's perfect for business users, operations teams, analysts, and designers who need to automate workflows without touching code.
But it's not for developers. And that's fine — it was never meant to be.
Developers have their own tools: GitHub Copilot (enterprise), Claude Code, Cursor, Codex CLI. These tools embed AI directly into the IDE, understand codebases at a structural level, and integrate with version control and CI/CD pipelines. A developer building an API endpoint doesn't need a visual agent builder — they need inline code generation, intelligent autocomplete, and refactoring assistance.
This split is becoming the new normal across the industry. According to recent data, the ratio of citizen developers (business technologists) to professional software engineers is approaching 4:1 in 2026. By some estimates, roughly 40% of enterprise software is now built using natural-language-driven "vibe coding" where prompts guide AI to generate working logic.
The fusion team model is the pattern emerging for high-performing organizations: professional developers transition into "Platform Architects" and "Component Builders," creating complex, reusable modules. Business users then drag-and-drop these components into workflows via low-code platforms.
This isn't a competition. It's specialization. The agent builder serves one audience; CLI-based AI dev tools serve another.
The reality check: If your organization is rolling out an internal agent platform, be explicit about who it's for. Don't oversell it to developers who already have better tools. And don't undersell it to business users who could genuinely benefit.
What Agent Builders Are Actually Good At (And What They're Not)
During the training, the demos showcased impressive use cases: drafting proposals, answering HR policy questions, routing support tickets, generating creative briefs. These are all legitimate wins. But as I thought through what my team actually does day-to-day, a pattern emerged.
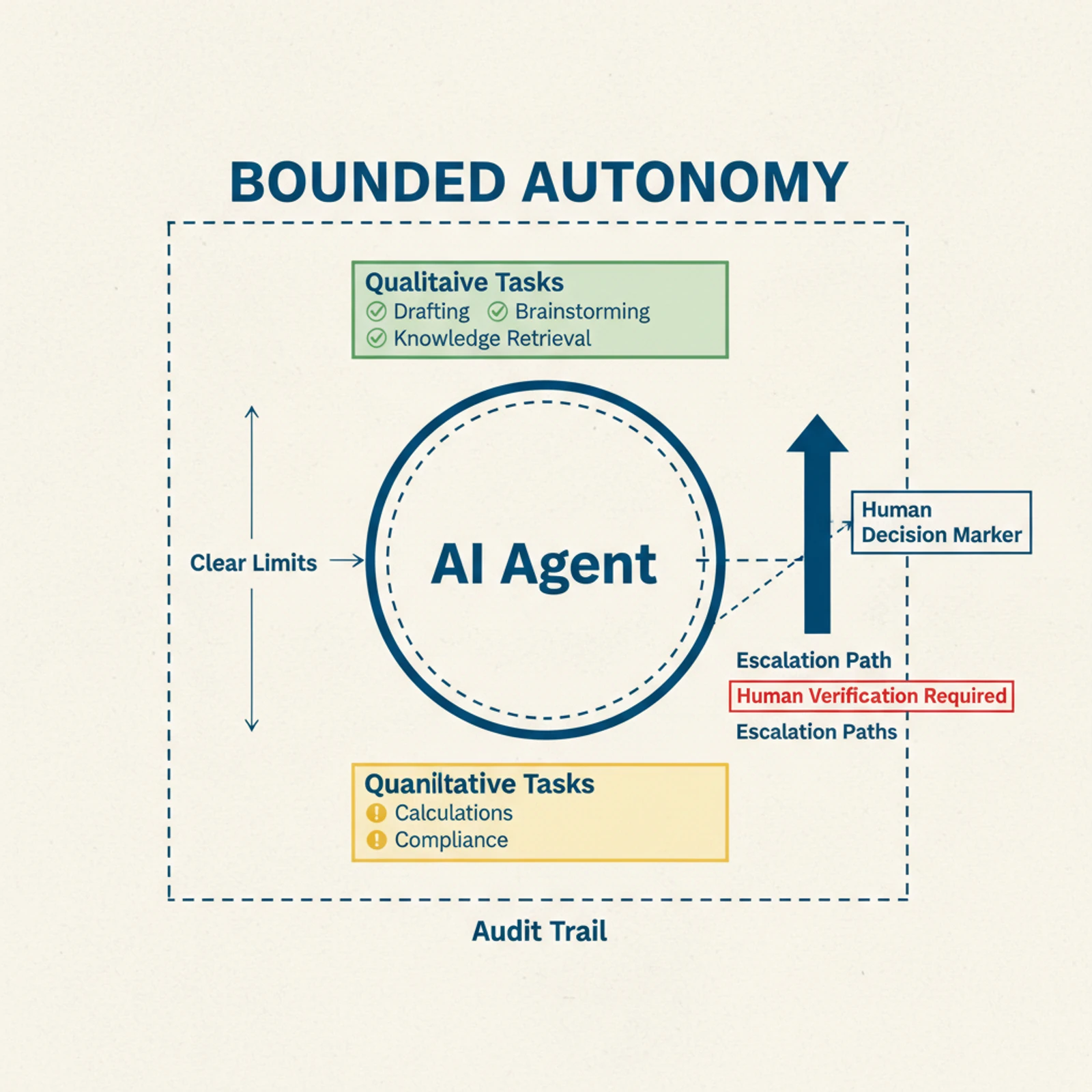
Agent builders excel at qualitative work:
- Drafting, editing, and formatting content
- Brainstorming ideas and generating creative alternatives
- Answering questions from unstructured knowledge bases
- Workflow automation for repetitive business processes
Agent builders struggle with quantitative work:
- Financial calculations that must be 100% accurate
- Statistical summaries where a small error cascades into client-facing reports
- Compliance checks that require precise matching against regulatory criteria
- Any process where verifying every number from scratch is impractical
This isn't a flaw in the technology — it's the nature of probabilistic systems. An LLM generating a beautifully formatted proposal is applying pattern recognition to language. If one sentence is slightly off-tone, it's a minor issue. But an LLM calculating a revenue projection that's off by 3%? That's a problem.
The practical implication: use AI agents for what they're good at, and keep humans in the loop for what they're not. The industry is moving toward "bounded autonomy" architectures with clear operational limits, escalation paths to humans for high-stakes decisions, and comprehensive audit trails of agent actions.
Gartner's prediction that 40% of enterprise applications will embed AI agents by the end of 2026 is probably right. But those agents will handle narrow, well-scoped tasks — not open-ended decision-making in critical workflows.
The Security and Governance Gap Nobody Talks About
The session spent maybe five minutes on security and governance. The message was clear: "We've got SOC 2 compliance, role-based permissions, and audit logs." All true. But those are baseline controls for traditional software.
AI agents introduce a fundamentally different threat model.
Here's what the broader industry is seeing:
- 88% of organizations had confirmed or suspected AI security incidents in 2025
- Only 14.4% of organizations have full security approval for their entire agent fleet
- On average, only 47% of an organization's AI agents are actively monitored or secured
- More than half of all agents operate without any security oversight or logging
The risks aren't hypothetical:
- Prompt injection: Malicious content in documents or knowledge bases that hijacks agent behavior
- Data leakage: The agent accidentally includes sensitive information in responses
- Privilege escalation: The agent takes actions beyond its intended scope
- Compliance drift: Business users configure agents that inadvertently violate data protection regulations
For consulting firms like Deloitte, Accenture, and similar organizations, this is existential. A single data leak via a poorly configured agent can destroy client trust and trigger regulatory penalties. That's why governance isn't an afterthought — it's the primary value proposition of an internally built agent framework.
The good news: mature governance frameworks are emerging. Leading organizations are implementing:
- Pre-approved tool libraries that agents can access (not open-ended API access)
- Human-in-the-loop approvals for high-stakes actions
- Real-time monitoring with anomaly detection for unusual agent behavior
- Automated compliance checks before agents are deployed to production
But here's the tension: governance slows down the "democratization" pitch. If every agent configuration requires security review before deployment, you're back to bottlenecks. The balance between speed and control is still being figured out.
The reality check: If your organization is serious about AI governance, the internal agent platform is actually an advantage. You control the framework, the tool permissions, and the compliance checks. External platforms (even enterprise-grade ones) require trusting a third party's security model.
But that only works if governance is built in from day one — not bolted on after incidents start happening.

The Framework Evolution Problem: Tech Debt Is Inevitable
One of the more interesting discussions during the training was about future extensibility. The platform currently supports a fixed set of pre-built tools — database queries, document retrieval, API calls to approved services. The roadmap includes support for custom tool integration.
This is where things get tricky.
AI agent frameworks are evolving at a pace that makes web frameworks look stable. When many organizations started building internal agent platforms in 2023–2024, the Model Context Protocol (MCP) was the hot new standard for connecting agents to external tools. Then Anthropic open-sourced the Skills format in late 2025, providing a complementary approach where Skills define the "how-to" workflows and MCP defines the "with-what" integrations.
In December 2025, Anthropic donated MCP to the Linux Foundation's Agentic AI Foundation. The protocol is now governed by a consortium including Anthropic, OpenAI, Block, and others. That's a strong signal that MCP will be around for a while.
But the user also mentioned frameworks like Manus (recently acquired by Meta for $2B) and OpenClaw (a next-generation proactive agent framework). The ecosystem is churning.
The trade-off every company faces: Build a proprietary agent framework that you control, or adopt an open standard that evolves independently. Neither is wrong. But both come with tech debt:
- Proprietary frameworks require ongoing maintenance to keep up with model capabilities and security standards
- Open frameworks require frequent refactoring as the community shifts between patterns
For most enterprises, the bet is pragmatic: start with a constrained, governed platform that solves 80% of use cases. Accept that the framework will need periodic updates. Plan for extensibility (custom tools, MCP integration, Skills support) but don't try to support everything on day one.
The alternative — waiting for the "final" agent standard to emerge — means waiting indefinitely. The technology is moving too fast.
The reality check: If your company chose to build an internal agent framework, they're making a bet on governance and control over bleeding-edge flexibility. That's the right call for most regulated industries. Just don't expect the framework to remain static.
The Data Foundation Question: Don't Reinvent the Wheel
Here's something the training session didn't cover, but it's arguably the most important question for enterprise AI agents: where does the data come from?
Our internal agent platform currently doesn't integrate with enterprise data systems — the data warehouse, OneDrive, SharePoint, or structured databases. You can upload documents to a knowledge base, but there's no native connection to where the actual business data lives. And that's a problem, because the value of an AI agent is directly proportional to the data it can access.
This is where the "don't build what already exists" principle becomes critical.
The Enterprise Data Platform Landscape
The good news: the major data platforms have already solved this problem. They've spent years building the infrastructure to make enterprise data AI-ready, and they're now offering it as a managed service.
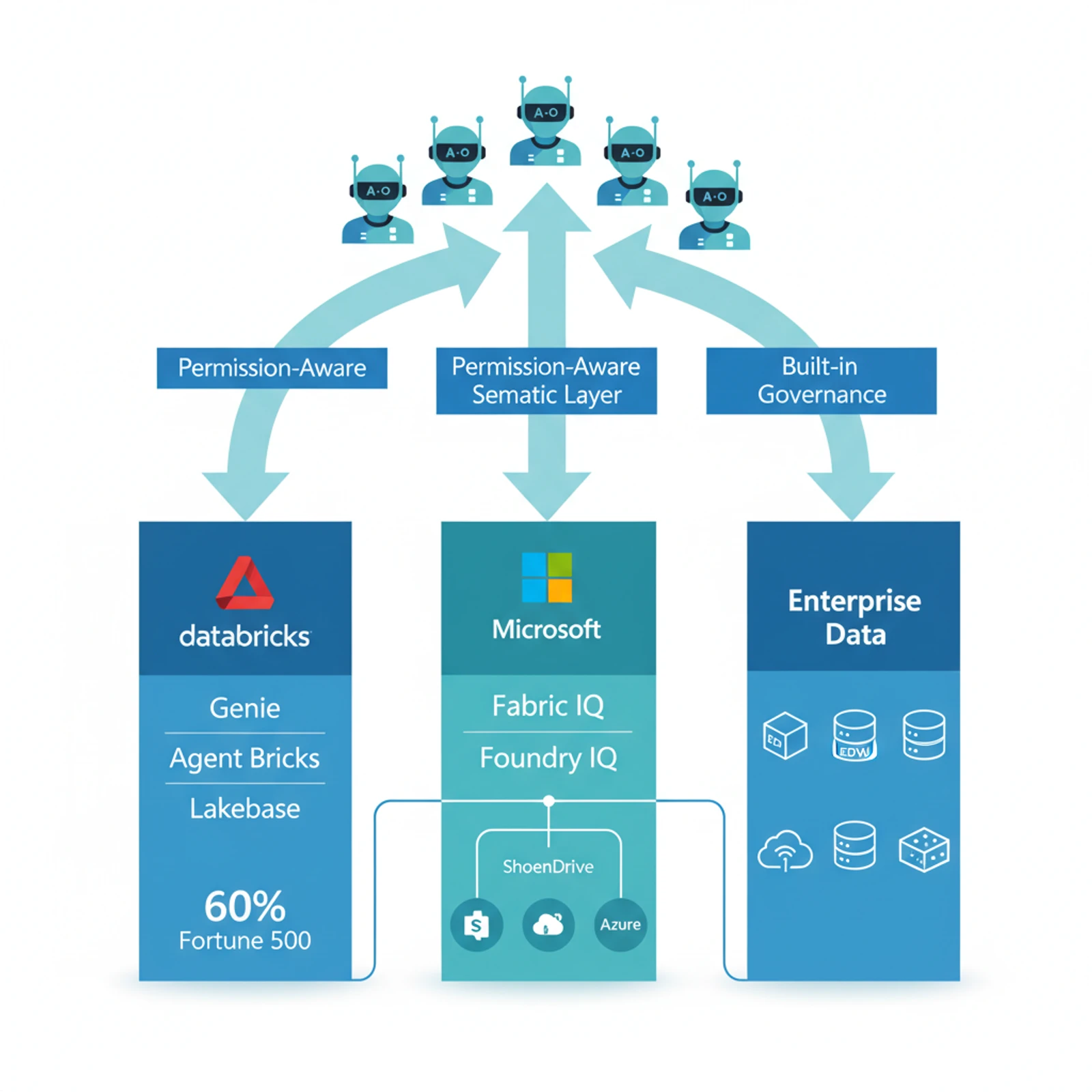
Databricks Genie & Agent Bricks is the standout example. Databricks Genie (now generally available) is a conversational AI assistant that lets employees ask questions about company data in plain language instead of writing SQL or building dashboards. Business users can ask "How is my sales pipeline?" and Genie answers with text summaries, tables, and visualizations — all grounded in the data already stored in Databricks.
The architecture is elegant: the data already exists in Databricks (lakehouse platform), Genie connects directly to it, and the agent inherits all the existing governance, access controls, and data quality rules. No data duplication. No complex ETL pipelines to keep agents in sync with reality.
Databricks is doubling down on this with Lakebase (a serverless Postgres database built specifically for AI agents) and Agent Bricks Supervisor Agent (now GA) for orchestrating multiple enterprise agents. With over 20,000 organizations using Databricks — including 60% of the Fortune 500 — the data foundation is already in place for millions of potential AI agents.
Microsoft's Fabric IQ + Foundry IQ takes a similar approach but across the Microsoft ecosystem. Fabric IQ is the semantic foundation that brings together data, meaning, and actions into a single layer. Foundry IQ is the managed knowledge layer that connects structured and unstructured data across Azure, SharePoint, OneLake, and the web.
The key capability: Foundry IQ makes enterprise data permission-aware. When an AI agent queries data, it respects the same access controls that govern human users. If you don't have permission to see a file in SharePoint, the agent won't surface it in responses. This is crucial for enterprise deployment — you can't have agents leaking data across organizational boundaries.
On February 3, 2026, Microsoft launched AI agents in OneDrive for commercial users worldwide, with the ability to analyze up to 20 documents simultaneously. The integration with SharePoint and Teams means agents can access the unstructured knowledge (documents, presentations, emails) alongside structured data (databases, analytics).
The pattern is clear: the data platforms are becoming intelligence platforms. They're not just storing data — they're providing the semantic layer, the access controls, the governance, and the agent orchestration infrastructure.
The Build vs. Buy Reality for Data Foundations
When building an internal agent framework, the temptation is to build everything — the agent orchestration, the tool integrations, and the data layer. But the data layer is where "build" becomes a strategic mistake for most organizations.
The reason: DataOps is a full-time job. Making enterprise data AI-ready requires automation, orchestration, observability, testing, and governance. It requires handling schema changes, data quality issues, access control updates, and lineage tracking. The primary reason autonomous agents fail in production is often data hygiene issues — the agent gets stale data, misinterprets a schema change, or accesses data it shouldn't.
The successful pattern emerging in 2026 isn't "build or buy" — it's hybrid assembly:
- Buy the data foundation from your existing data platform (Databricks, Fabric, Snowflake, etc.)
- Buy foundation models and pre-built domain agents
- Build custom workflows, business logic, and agent orchestration on top
- Connect everything under shared governance rails
This approach leverages the billions of dollars Databricks, Microsoft, and others have invested in making data AI-ready. You're not duplicating that effort — you're building the layer that's unique to your business.
What This Means for Internal Agent Platforms
If your company is building an internal agent platform, the strategic question is: how does it connect to where the data actually lives?
The agent framework that doesn't integrate with the enterprise data warehouse, SharePoint, OneDrive, and operational databases is solving the easy part (agent orchestration) while ignoring the hard part (data access). And without data, even the most sophisticated agent is just an expensive chatbot.
The good news: you don't need to build this from scratch. If your organization uses Databricks, leverage Genie and Agent Bricks. If you're in the Microsoft ecosystem, use Fabric IQ and Foundry IQ. If you're on Snowflake, explore Cortex AI. These platforms have already done the work.
The reality check: The internal agent builder is valuable for workflow automation and knowledge retrieval from curated documents. But if the vision is "agents that help employees make data-driven decisions," the framework needs a data strategy that goes beyond document uploads. Fortunately, the platforms to enable that already exist — the question is whether the agent framework is designed to integrate with them.
What I'll Actually Use (And What I Won't)
After the training, I thought through my own workflow. What will genuinely change?
What I'll use the internal agent builder for:
- Drafting proposals and presentations — the agent can pull from internal case studies, apply brand formatting, and generate first drafts faster than I can
- Answering policy questions — our internal knowledge base is massive; an agent that retrieves and summarizes is genuinely helpful
- Brainstorming and creative exploration — multiple angles on a problem, rapid iteration on ideas
What I'll stick with GitHub Copilot (enterprise) for:
- Code generation and refactoring — Copilot understands the codebase context better than a generic agent builder
- Inline autocomplete and suggestions — the IDE integration is seamless
- Debugging and test generation — Copilot's code-native design is a better fit
What I'll keep watching:
- Anthropic's enterprise partnerships — I saw a report recently that Anthropic started cooperating with the U.S. military, which suggests their data protection and security frameworks are maturing. If Anthropic's Claude Gov models (FedRAMP High certified) become available for enterprise use, tools like Claude Code could become viable in strictly governed environments.
- The gap between "enterprise allowed" and "actually good" — GitHub Copilot is the approved tool, but it has significant gaps compared to Claude Code, Cursor, and even Antigravity. If security certifications catch up with capabilities, the landscape shifts quickly.
The reality check: The internal agent builder is a good tool for business workflows. But it's not a replacement for developer-focused AI tools. Use both where they make sense, and don't try to force one to do the other's job.
The Hype Cycle vs. The Deployment Cycle
Here's the gap that's easy to miss in the excitement: the hype cycle and the deployment cycle are running on different timelines.
The hype cycle says: "AI agents are here! Everyone can build them! Autonomous AI workforce!"
The deployment cycle says: "Start with FAQ bots. Expand to workflow automation. Test rigorously. Monitor closely. Scale cautiously."
The AI agent market is projected to grow from $7.84 billion in 2025 to $52.62 billion by 2030. That's real momentum. But Gartner also predicts that 40% of agentic AI projects will fail by 2027 due to complexity management, not technical limitations.
The pattern I'm seeing across the industry: companies that succeed with AI agents start with bounded, high-value use cases and expand incrementally. The ones that fail try to build an "autonomous AI workforce" on day one without understanding the coordination overhead, error recovery requirements, or governance implications.
The internal agent builder my company introduced is genuinely impressive. It lowers the barrier to entry for AI-powered workflows in a way that will unlock real productivity gains across non-technical teams. But it's not magic. It's a tool with a specific use case, a specific audience, and specific limitations.
The most valuable thing the training did wasn't the demos — it was showing people what's actually possible right now, not in some speculative future. And right now, what's possible is:
- Business users building agents for qualitative, creative, and knowledge-retrieval tasks
- Developers using AI-native coding tools that integrate directly into their workflow
- Governance teams implementing bounded autonomy to manage risk
- Organizations learning what works through careful, incremental deployment
That's not as exciting as "AI replaces your job." But it's a lot more useful.
Wrapping Up
The internal AI agent builder training was excellent. The platform is genuinely good at what it does. And the vision of democratizing AI across the organization is the right direction.
But democratization doesn't mean everyone does everything. It means the right people have access to the right tools for the right tasks. Low-code agent builders are powerful for business workflows, creative processes, and knowledge management. They're not a replacement for developer tooling, and they're not ready for high-stakes quantitative work without human oversight.
The companies that get this right will be the ones that:
- Clearly define who the tool is for (and who it's not for)
- Start with bounded, high-value use cases instead of trying to automate everything at once
- Invest in governance from day one instead of treating it as an afterthought
- Accept that the framework will evolve and plan for periodic refactoring
AI agents are becoming infrastructure. Not in the hype-cycle sense, but literally — embedded into daily workflows, governed by enterprise policies, and scaled incrementally as the technology matures.
The experimental phase isn't over. But it's no longer the main story.
Sources:
- AI agent trends for 2026: 7 shifts to watch - Salesmate
- Top Agentic AI Trends to Watch in 2026 - CloudKeeper
- State of AI Agent Security 2026 Report - Gravitee
- 7 Agentic AI Trends to Watch in 2026 - MachineLearningMastery
- Claude Security Explained: Benefits, Challenges & Compliance - Reco.ai
- Claude Gov models for U.S. national security customers - Anthropic
- Understanding Agent Skills and MCP: The Future of No-Code Workflow Automation - Medium
- Agent Skills vs MCP: Two Standards, Two Security Models - Friedrichs-IT
- Databricks Doubles Down on AI With Lakebase, Genie - BigDATAwire
- AI/BI Genie is now Generally Available - Databricks Blog
- Agent Bricks Supervisor Agent is Now GA - Databricks Blog
- Introducing Microsoft Fabric IQ - Microsoft Fabric Blog
- Fabric IQ: The Semantic Foundation for Enterprise AI - Microsoft Fabric Blog
- What is Foundry IQ? - Microsoft Learn
- Microsoft Launches AI Agents in OneDrive - WinBuzzer
- Enterprise AI strategy: why buy often beats build - Fintech Global
- Build vs. Buy AI Agents: A Strategic Guide - Turing