You built a RAG prototype. It works on your ten test documents. Your demo goes well. Then production happens.
Users ask questions your chunking strategy can't handle. The system hallucinates a statistic that doesn't exist in any of your documents. Someone queries in Portuguese and gets English fragments mixed into the response. Your boss asks "how many contracts exceeded $1 million last quarter?" and the LLM confidently returns a wrong number because it can't actually count across 200 PDFs.
RAG is the most accessible pattern in the AI toolbox — and one of the most deceptive. The gap between a working prototype and a reliable production system is where most teams get burned. This post maps the pain points I've hit (and seen others hit) across real projects, and the solutions that actually move the needle.
Pain Point 1: Chunking — The Silent Killer
Chunking is where most RAG systems quietly fail. Not with an error message, but with subtly wrong answers that erode trust over weeks.
The fundamental tension: chunks need to be small enough for precise retrieval, but large enough to carry meaning. Get this wrong and everything downstream suffers — your embeddings encode incomplete ideas, your retriever returns fragments instead of answers, and your LLM hallucinates to fill the gaps.
What goes wrong in practice:
- Mid-sentence splits break logical units. A chunk ends with "The contract value was" and the next starts with "$2.3 million for the Dublin office." Neither chunk alone answers the question.
- Tables lose structure. Standard text splitters shred tabular data into meaningless rows. The header ends up in one chunk, the data in another.
- Context evaporates. A paragraph referencing "the policy described above" becomes meaningless when "above" lives in a different chunk.
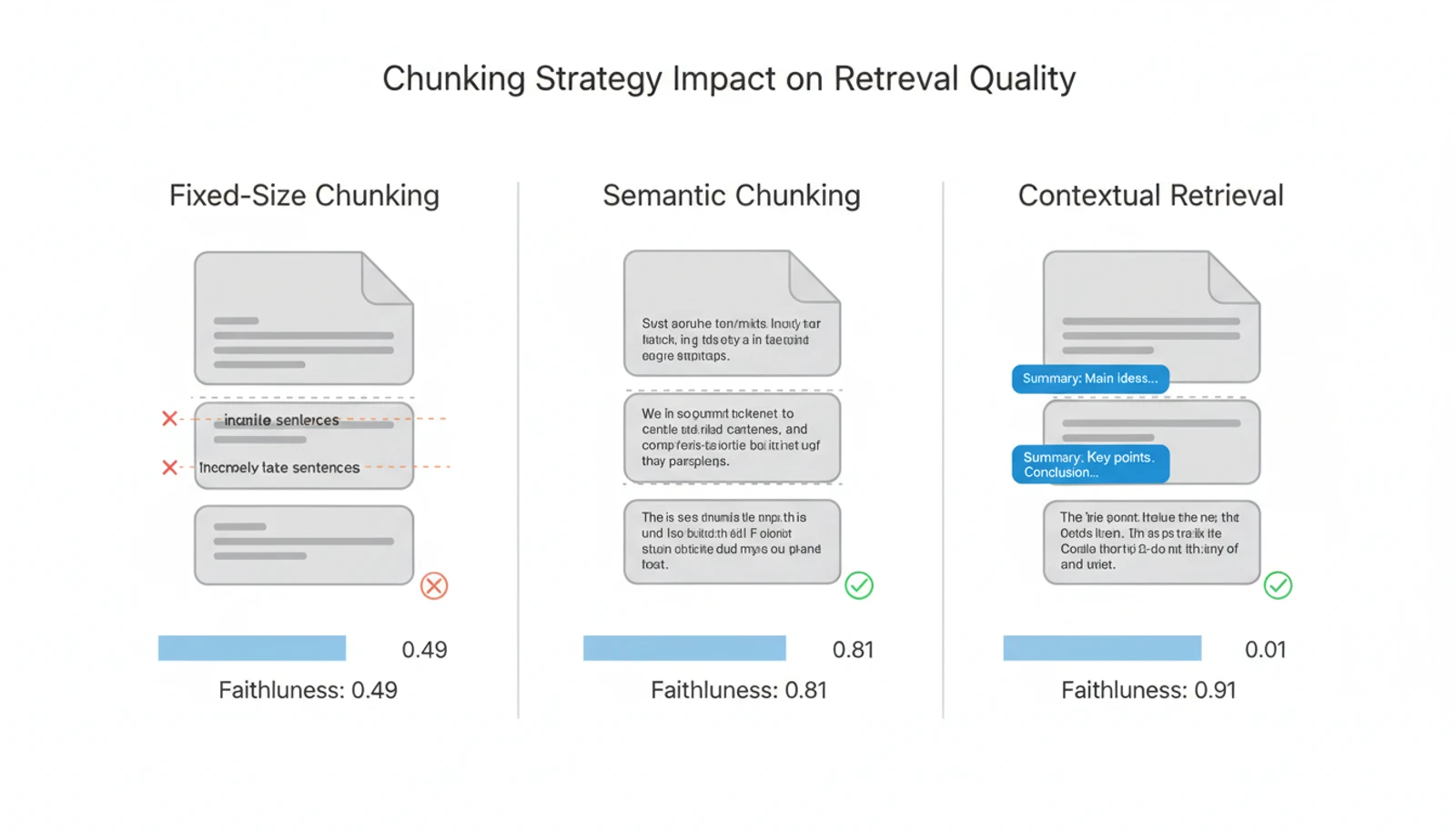
A 2025 CDC policy study comparing chunking strategies found that naive fixed-size chunking scored 0.47-0.51 on faithfulness, while optimized semantic chunking hit 0.79-0.82 — a gap large enough to be the difference between a useful system and a dangerous one.
What actually works:
Semantic chunking splits at natural boundaries — paragraph breaks, section headers, topic shifts — rather than arbitrary token counts. It costs more (you need an embedding model to detect boundaries), but the retrieval quality improvement is substantial.
Contextual retrieval, introduced by Anthropic in September 2024, takes a different approach: before embedding each chunk, prepend a brief summary (under 100 words) of the document context. This reduced failed retrievals by 49%, and by 67% when combined with reranking. The idea is simple — if a chunk says "this policy," the prepended context clarifies which policy.
Overlap is cheap insurance. Industry consensus sits at 10-20% overlap between adjacent chunks — enough to preserve boundary context without bloating your index.
And don't overthink it at the start. Research consistently shows that chunking quality constrains retrieval accuracy more than embedding model choice. Fix your chunking before upgrading your embeddings.
Pain Point 2: "How Many...?" — RAG Can't Count
This is the one that surprises teams the most.
Ask your RAG system "What is our refund policy?" and it works beautifully — retrieve the right chunk, generate a clear answer. Now ask "How many support tickets were escalated last month?" and watch it fall apart.
Why: RAG is architecturally designed for similarity search, not aggregation. Vector databases find similar content, not all matching content. When a question requires scanning an entire dataset, counting rows, summing values, or computing averages, the retrieve-then-generate pattern fundamentally cannot deliver.
The problem compounds with scattered data. If KPIs live across 50 reports in different formats — some in tables, some in paragraph text, some in chart captions — no amount of chunking finesse will let a similarity search aggregate them correctly.
What actually works:
Text-to-SQL for structured queries. When the question is quantitative, route it to SQL. SQL has built-in aggregation, handles larger datasets than any context window, and returns deterministic results. Tools like LlamaIndex's SQL agents and LangChain's SQLDatabaseChain bridge the gap.
Pre-computed metadata. For statistics you know users will ask about, compute them at ingestion time and store them as metadata. "Total contract value: $4.2M" as a metadata field is infinitely more reliable than asking the LLM to find and sum every dollar amount across your corpus.
Hybrid routing. Not every question needs the same pipeline. A query classifier can route "What does the policy say about..." to RAG and "How many..." to SQL or a structured data agent. We'll dig into routing in Pain Point 4.
Pain Point 3: Hallucination — When RAG Invents Its Sources
RAG was supposed to solve hallucination. It helps. It doesn't eliminate it.
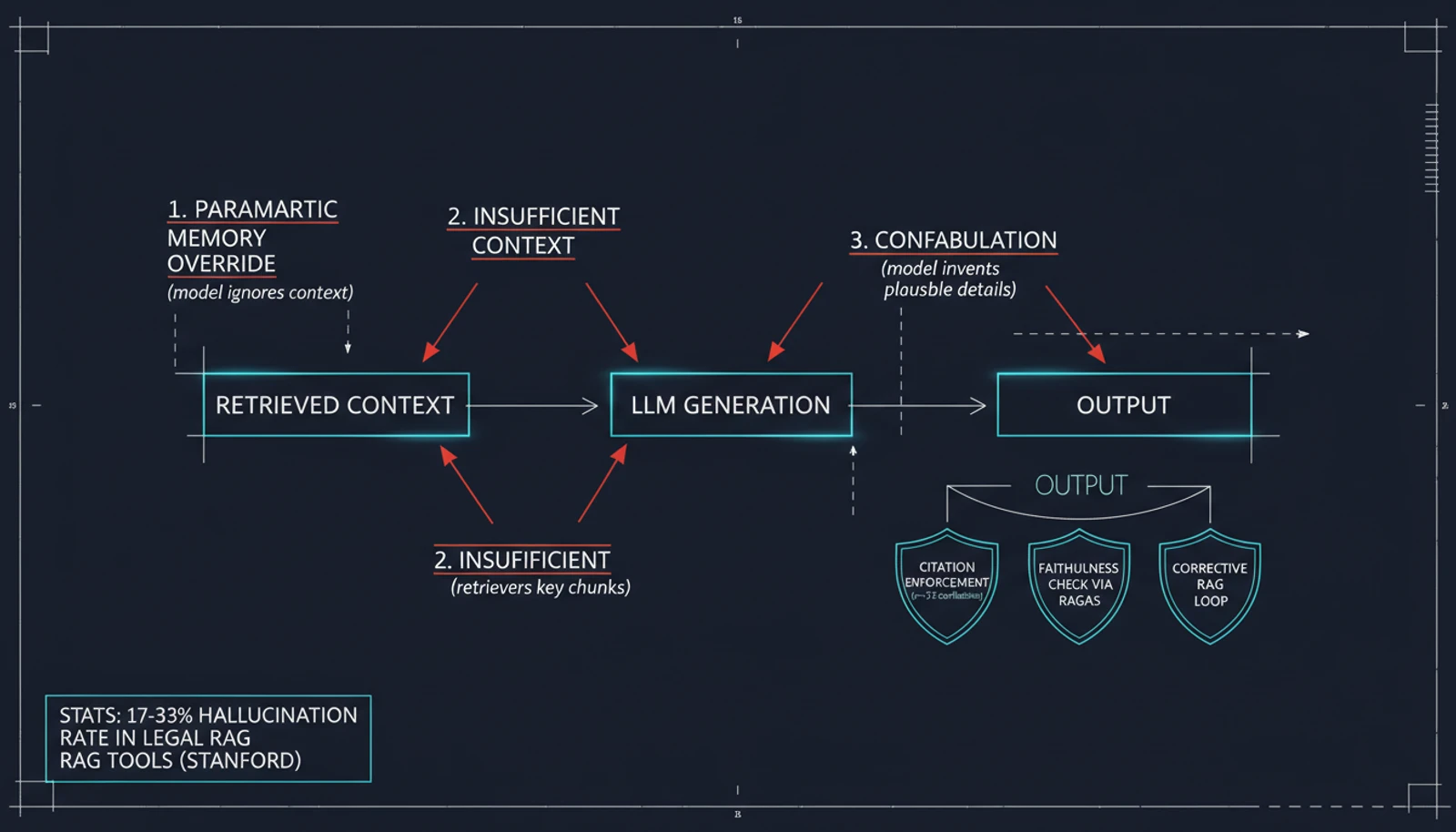
A Stanford study of RAG-based legal AI tools from LexisNexis and Thomson Reuters found hallucination rates between 17% and 33% — in production legal tools where accuracy is existential. The system retrieves real documents, then the LLM confabulates details that aren't in those documents, sometimes even fabricating citations that look plausible but don't exist.
Why it persists: The LLM's parametric memory (what it learned during training) can override the retrieved context. If the model "knows" something that contradicts the retrieved chunk, it sometimes trusts itself over the evidence. This is especially problematic for domain-specific or proprietary knowledge where the model's training data is stale or absent.
What actually works:
Citation enforcement. Research shows a strong negative correlation (r = -0.72) between citation rate and hallucination rate — forcing the model to cite specific passages for every claim measurably reduces fabrication. Implement this in your system prompt: every factual claim must reference a specific retrieved chunk.
Faithfulness evaluation. Use RAGAS metrics — particularly faithfulness (is the answer supported by the context?) and context precision (did the retriever rank relevant chunks highest?). Measuring these on a test set before deployment catches problems early.
Guardrails and verification loops. Post-generation checks that cross-reference claims against retrieved chunks can catch hallucinations before they reach users. Corrective RAG takes this further — if the retrieved context seems insufficient, the system re-retrieves or declines to answer rather than guessing.
Constrained generation. For high-stakes domains (legal, medical, financial), consider constraining the LLM to only quote or paraphrase retrieved text, rather than generating free-form responses. Less creative, but far more reliable.
Pain Point 4: Everything Looks Like a Nail — Query Intent Matters
A customer types "hey, how's it going?" into your RAG-powered chatbot. The system dutifully searches your knowledge base for documents about "how's it going," retrieves something vaguely related, and generates a bizarre, overly formal response grounded in your product documentation.
This is the intent problem. Not every message is a knowledge query. Some are greetings. Some are complaints. Some are requests that need action, not information. Treating everything as a retrieval task wastes compute, increases latency, and produces awkward interactions.
What actually works:
Semantic routing. Classify queries before they hit the retrieval pipeline. A lightweight classifier (or even embedding-based similarity to pre-defined intent clusters) can sort incoming messages into categories: social/greeting, product query, complaint, action request. Each category gets a different handler.
One team reported cutting AI API costs by 95% with intelligent routing — simple questions got cached responses or lightweight models, while only complex queries triggered the full RAG pipeline.
Tier-based processing:
| Intent | Handler | RAG Needed? |
|---|---|---|
| Social greeting | Template response | No |
| FAQ / common question | Cached answer | No |
| Product-specific query | Full RAG pipeline | Yes |
| Aggregation / analytics | SQL agent | No (different pipeline) |
| Complaint / escalation | Human handoff | No |
The routing doesn't need to be perfect. Even rough classification dramatically improves both response quality and cost efficiency.
Pain Point 5: Agent vs. RAG App — Knowing When RAG Isn't Enough
I've seen teams twist RAG into shapes it was never meant to hold. Multi-step research tasks, workflows that require taking actions, queries that need real-time data — all forced through a retrieve-then-generate pipeline that can only do one thing: find similar text and summarize it.
The honest comparison:
RAG is a pattern — query, retrieve, generate. It's stateless, single-turn, and fast. An AI agent is a system — it plans, uses tools, maintains state, and iterates. They solve different problems.
| Dimension | RAG Application | AI Agent |
|---|---|---|
| Latency | Fast (single retrieval) | Slower (multi-step reasoning) |
| Cost per query | Low | Higher (multiple LLM calls) |
| Complexity | Simple pipeline | Orchestration, tool management |
| Best for | Knowledge Q&A, documentation | Research, workflows, actions |
| Real-time data | Needs re-indexing | Can query APIs directly |
The evolution path is clear: simple RAG → Advanced RAG (re-ranking, hybrid search) → Agentic RAG (agents that use retrieval as one tool among many). Research benchmarks show Cache-Augmented Generation completing queries in 2.33 seconds versus traditional RAG's 94.35 seconds for cacheable corpora — a 40x improvement — suggesting that for static knowledge bases, caching may eventually replace retrieval entirely.
The practical decision: If your use case is "answer questions about these documents," RAG is right. If your use case is "research this topic, check multiple sources, take action based on findings," you need an agent. Most production systems end up being agents that use RAG as one of their tools.
Pain Point 6: The Multilingual Minefield
Your RAG system works brilliantly in English. Then you deploy it for your German office. Or your Japanese team. Or your Brazilian customers. And things get weird.
The core issues:
Embedding model bias. Most embedding models were trained primarily on English data. Cross-lingual retrieval performance drops 30-50 points (Hits@20) compared to same-language retrieval. A query in Spanish searching an English corpus might miss relevant documents that a same-language query would catch easily.
Response language inconsistency. Even with monolingual retrieval, models struggle with response language correctness — answering in the wrong language, mixing languages mid-sentence, or transliterating named entities incorrectly.
Cultural context loss. This is subtle but real. RAG can amplify biases in retrieved documents, and in multilingual contexts, cultural assumptions embedded in one language's documents may not translate.
What actually works:
Multilingual embedding models like Cohere's embed-multilingual-v3 or OpenAI's text-embedding-3-large perform better than monolingual models for cross-lingual retrieval, though a gap remains.
Translation-first retrieval (CrossRAG). Translate all documents into a common language at ingestion time. This sounds crude but significantly outperforms cross-lingual embedding retrieval, especially for low-resource languages. The trade-off is storage (you're keeping multiple copies) and translation quality.
Language-aware routing. Detect the query language, retrieve from the matching language corpus when available, and only fall back to cross-lingual retrieval when same-language content doesn't exist.
There's no silver bullet here. The MTEB benchmark only covers English, Chinese, French, and Polish — if your users speak other languages, you're flying with limited instrumentation.
Pain Point 7: Beyond Text — Multimodal RAG Is Still Early
Your knowledge base isn't just text. It's architectural diagrams, recorded meetings, product photos, training videos, spreadsheets with charts. Users expect to query all of it. The reality is messier.
Where we are:
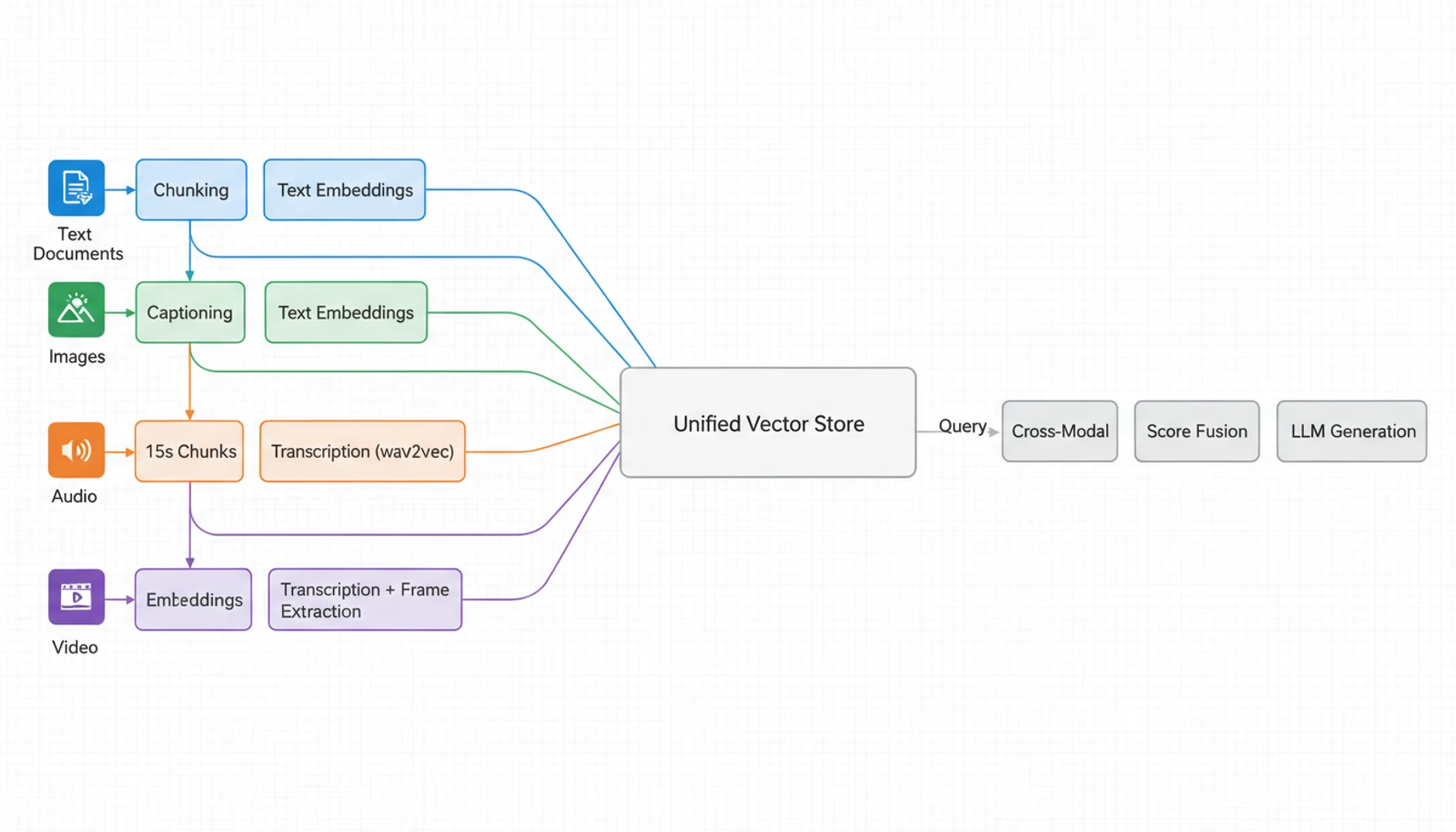
Text RAG is mature. Image RAG works for some use cases — models like CLIP can embed images alongside text, and vision-language models can describe what they see. But the integration is fragile.
Audio and video RAG is bleeding-edge. Platforms like Ragie now offer native audio/video support, and research suggests 15-second video chunks provide the best balance between context and information density. But the pipeline is complex: transcribe, embed, align timestamps, handle speaker diarization — each step introduces error.
The main challenges:
- Cross-modal alignment. How do you rank a text chunk against an image against an audio segment? Score fusion, feature fusion, and LVLM-based retrievers each have trade-offs.
- Embedding heterogeneity. Text embeddings and image embeddings live in different spaces unless you use unified models, and even then, the quality of cross-modal similarity search varies significantly.
- Output formatting. Generating responses that naturally interleave text, images, and audio references requires explicit orchestration — current frameworks need inserter modules that decide image placement at the sentence level.
Practical advice: Start text-only. Add structured data (tables, metadata) next. Image retrieval is ready for production if you use captioning + text embedding rather than pure visual embedding. Audio/video retrieval — evaluate carefully, set expectations with stakeholders, and plan for rapid iteration as the tooling matures monthly.
The RAG Maturity Path
After working through these pain points across projects, a pattern emerges. RAG isn't one thing — it's a spectrum, and knowing where you are on it helps you prioritize what to fix next.
| Stage | What It Is | Typical Issues |
|---|---|---|
| Naive RAG | Retrieve → Generate. No optimization. | Wrong chunks, hallucinations, no evaluation |
| Advanced RAG | Re-ranking, hybrid search, better chunking | Still single-turn, can't aggregate, no routing |
| Modular RAG | Swappable components, evaluation pipeline | Complexity cost, needs MLOps maturity |
| Graph RAG | Entity graphs, relationship-aware retrieval | Expensive to build, improves multi-hop QA by ~6.4 points |
| Agentic RAG | Agents orchestrating retrieval as one tool | Higher latency and cost, but handles complex reasoning |
Most teams I encounter are stuck between Naive and Advanced. The biggest bang for your buck usually isn't jumping to the latest paradigm — it's fixing your chunking, adding evaluation metrics, and implementing basic query routing. The fundamentals.
A Checklist Before You Ship
Before pushing your RAG system to production, run through this:
- Chunking audit. Test retrieval with real user queries, not your dev set. Check for broken context, shredded tables, and orphaned references.
- Evaluation baseline. Set up RAGAS or equivalent. Measure faithfulness, context precision, context recall, and answer relevancy. Know your numbers.
- Query routing. Not everything needs RAG. Classify intent and route accordingly.
- Aggregation strategy. If users will ask "how many" or "total of," have a plan. RAG can't count.
- Hallucination guardrails. Citation enforcement, faithfulness checks, or constrained generation — pick at least one.
- Metadata enrichment. Pre-computed statistics, document types, dates, entities — metadata makes filtering possible and retrieval precise.
- Multilingual plan. If you have non-English users, test cross-lingual retrieval explicitly. Don't assume it works.
- Monitoring. Log retrieved chunks alongside generated answers. When something goes wrong (it will), you need to trace whether the problem was retrieval, generation, or both.
Closing Thoughts
RAG's reputation as "easy" comes from prototyping. Building a demo that answers questions about a PDF takes an afternoon. Building a system that reliably answers thousands of diverse questions across thousands of documents, in multiple languages, without hallucinating, at production latency — that takes engineering.
The good news: the solutions exist. Better chunking, semantic routing, evaluation frameworks, hybrid architectures. The bad news: there's no shortcut. Each pain point requires understanding why it happens, not just applying a fix from a blog post.
The field is moving fast. Cache-Augmented Generation is challenging traditional retrieval for static corpora. Agentic RAG is absorbing simple pipelines into larger orchestration frameworks. Multimodal retrieval is becoming practical. But the fundamentals — good chunking, honest evaluation, appropriate routing — these will matter regardless of which paradigm wins next year.
Start with the fundamentals. Measure everything. And don't trust the prototype.
Sources:
- Anthropic — Contextual Retrieval
- RAGAS Documentation — Available Metrics
- IBM — RAG Problems Persist: Five Ways to Fix Them
- NVIDIA — Traditional RAG vs. Agentic RAG
- Stanford Legal RAG Hallucination Study
- RAGFlow — From RAG to Context: 2025 Year-End Review
- Meilisearch — 14 Types of RAG
- Neo4j — Advanced RAG Techniques
- Microsoft — Building Multilingual RAG Systems
- arXiv — Multimodal RAG Survey
- Weaviate — Chunking Strategies for RAG
- Droptica — Intelligent Routing Cut API Costs by 95%