I was on a video call with two friends a few weeks ago. They run a six-person engineering team. They were arguing.
Not about features. Not about deadlines. About AI tools.
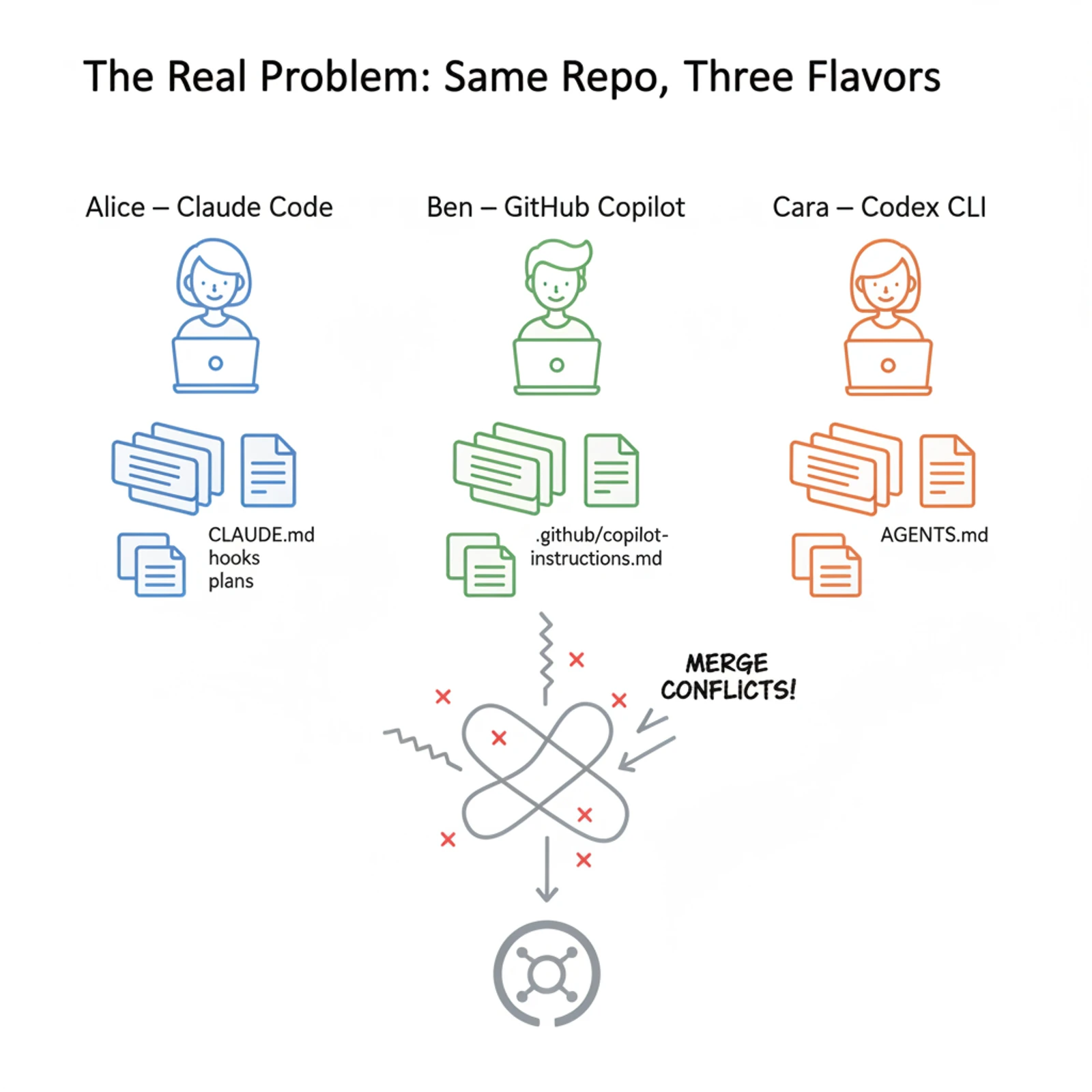
One of them — the tech lead — wanted everyone on Claude Code. Another had been a Copilot person since the beta. A third refused to give up Codex CLI. They'd just shipped a sprint of PRs, and the code, in his exact words, "looked like three different teams pretending to share a repo."
Lint passed. Tests passed. But the patterns disagreed. One developer's code leaned on React Server Components. Another's lived almost entirely in client hooks. Error-handling style drifted file by file. Even the commit messages couldn't decide on a tense.
He asked me what to do. He'd already looked at enterprise plans. They each have one — Anthropic's team plan, GitHub Copilot Business, the Codex enterprise tier. They give you SSO, audit logs, seat management. None of them solves the problem he actually had, which is that the code didn't look like it came from one project.
That conversation is what this post is about.
The thing nobody warns you about
Vibe coding works. I'm not skeptical of it anymore. I've shipped more software in the last six months than in the previous two years, and the tooling is now good enough that a single developer can carry the throughput of a small team. That part is real.
What's not real is the assumption that this scales cleanly to a team without anyone doing extra work.
Here's the part that surprised me. Enterprise SaaS controls — the ones you pay for at the org level — operate at the wrong altitude for the actual problem. SSO is great. Audit logs are great. But they don't tell Claude Code that your project uses pnpm, not npm. They don't tell Copilot that the team agreed last quarter to stop writing barrel exports. They don't tell Codex which test command to run before declaring a task done.
Those decisions live one floor down. At the project level. At the task level.
That's where governance has to actually happen. And almost nothing in your enterprise plan reaches that floor.
What teams try first (and why it doesn't hold)
The first instinct is to standardize on a single tool. My friends considered it. They tried it for a sprint.
It didn't last. People have preferences for real reasons. The Copilot person was faster in his IDE. The Claude Code person trusted the longer reasoning chains for non-trivial refactors. The Codex CLI person liked terminal-first workflows. Forcing them onto a single tool made everyone slower in different ways. Productivity dipped enough that they reverted within two weeks.
The second instinct is to write a long Slack message about the rules. That works for about a week. Then a contractor joins, or someone forgets, or the message scrolls into history and stops existing.
The third instinct — and this is where most teams stop — is to drop a CLAUDE.md at the root of the repo. That's a real improvement, but only if you happen to be using Claude Code. The Copilot user opens that file, says "interesting," and continues with whatever they were doing.
What's actually happening is that every tool has its own dialect. CLAUDE.md is for Claude Code. Cursor reads .cursor/rules. Copilot reads .github/copilot-instructions.md. Codex reads AGENTS.md. None of them read each other's files.
Three engineers, three tools, three separate instruction files — none of which anyone was keeping in sync.
The shift that changes everything
The thing that finally clicked was reframing the question. We'd been asking "how do we govern the tools?" The right question is "what do all the tools have in common?"
The answer is the repo. Every agent, regardless of vendor, runs against the same git tree. Every PR lands in the same branch. Every commit triggers the same CI.
So the governance has to live in the repo, not in the tools.
Once you accept that, the rest is mechanical. There are four layers worth building, in order.
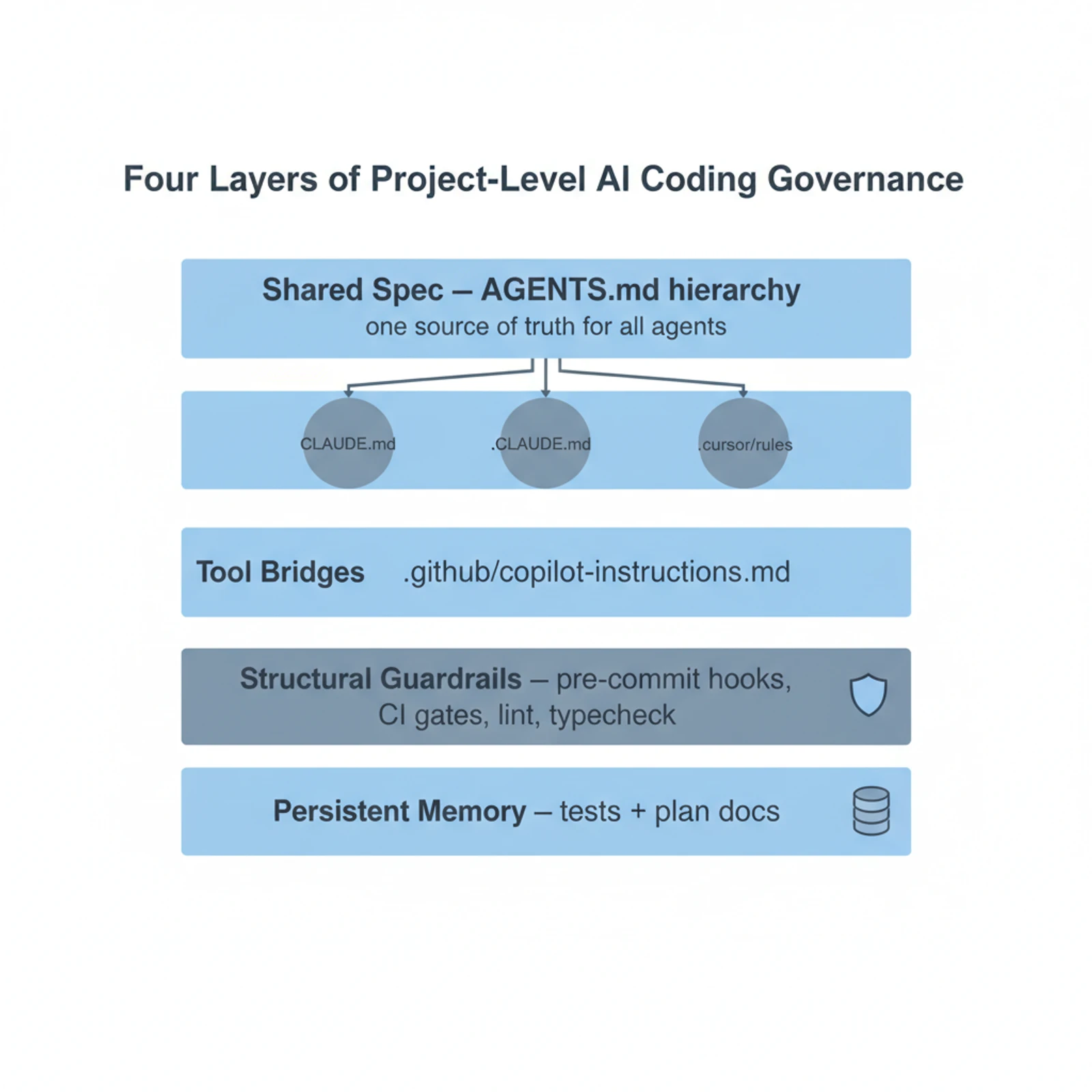
Layer 1: One spec, written once
Last August, OpenAI introduced a format called AGENTS.md. It's a plain Markdown file at the root of your repo. Codex reads it. So does Cursor. So does Factory. So does Amp. Google's Jules supports it. The format is now stewarded by the Linux Foundation under the Agentic AI Foundation. For the first time, there's a file format that every major coding agent agrees on.
Put your real rules there. The stack. The package manager. The test command. The architectural conventions. Whether barrel exports are allowed. How you handle errors. The commit-message style.
Keep it short. Under 300 lines is a healthy ceiling. If it crosses 500, the agents start ignoring most of it anyway. A focused 50-line file outperforms a sprawling 1,000-line one — that's been the consistent finding from people who measure it.
For monorepos, AGENTS.md is hierarchical. Drop one in each subdirectory, and the closest file to the work being done wins. apps/web/AGENTS.md can carry Next.js conventions while apps/api/AGENTS.md carries Go service rules, with a thinner global file at the root tying them together.

Layer 2: Tool-specific bridges that point home
Now you have a problem. AGENTS.md is the emerging standard, but Claude Code doesn't read it natively yet. Copilot reads its own file. So do a few others.
The fix is unglamorous: one-line bridges. Make CLAUDE.md a single line that says "See AGENTS.md." Same for .github/copilot-instructions.md. Same for .cursor/rules. Each tool reads its own dialect file and gets redirected to the canonical source.
You'll occasionally want tool-specific overrides — Claude Code sub-agent definitions, Copilot custom instructions for inline completion behavior. Put those in the dialect file, after the redirect. Everything universal lives in AGENTS.md and only AGENTS.md.
This is the unfashionable answer, but it's the working one. The repo is the source of truth. The dialect files are just adapters.
Layer 3: Rules in prompts are advisory. Rules in hooks are structural.
This is the line that took me longest to internalize. An instruction in a markdown file is a suggestion. The agent reads it, weighs it against thousands of other tokens of context, and might or might not follow it.
A pre-commit hook is not a suggestion.
If your AGENTS.md says "run the test suite before committing" and the agent skips that step, the commit goes through anyway. If your .husky/pre-commit runs pnpm test and exits non-zero on failure, the commit cannot go through. Different category of thing.
For a team using multiple AI tools, this matters more than it sounds. You can't trust each agent to enforce the same standard with the same vigor — they're trained differently, they read context differently, and on a long task even the disciplined ones cut corners. But you can trust git. Pre-commit hooks, lint-staged, type-check on push, branch-protection rules, CI gates — these are vendor-neutral. They work whether the code came from Claude Code, Copilot, Codex, or a human typing every character.
The mental shift to make: take any rule you've already written into AGENTS.md three different ways, and ask whether it can be a hook instead. If it can, move it. The markdown file is for things you can only express in prose. Everything else belongs in code.
Layer 4: Tests are the only memory the team shares
I wrote about this at length a couple of months ago, so I'll be brief here. AI agents have no memory between sessions. Different agents have no memory of each other ever. The thing that survives all of it — that catches the regression no human will spot in review, that flags when a new contributor's Copilot session has quietly broken something three folders away — is the test suite.
Tests are the only durable record of what the team actually agreed about behavior. Plan documents committed to the repo serve the same purpose for intent. Together they form a memory that doesn't depend on whose tool generated which line.
In a multi-tool team this is not optional. Without it you don't have a project. You have three running impressions of one.
Putting it together
The team I started this story with took about two weeks to refactor their setup. They wrote a 180-line AGENTS.md. They added one-line bridges in CLAUDE.md, .cursor/rules, and the Copilot file. They installed husky with a pre-commit hook that runs lint, typecheck, and the relevant test slice. They added a CI workflow that fails the PR if the full test suite breaks. They wrote a short PR template that asks the author to link the plan doc and the AGENTS.md sections that govern the change.
The next sprint, the PRs looked like they came from one team. Not because anyone had given up their preferred tool — everyone kept using what they liked — but because the rules of the game had moved out of the chat window and into the repo.
This isn't a productivity hack. It's not a new tool. It's the unglamorous realization that the only thing all your AI agents share is the codebase you're already paying for, and that's where governance has to live.
The enterprise plan covers seats, security, and billing. Useful, at the wrong floor. The project's job is to govern itself. The repo is the only contract every agent — every tool, every developer, every future AI nobody's launched yet — actually signs.
Which means the most leveraged thing a team can do this quarter is not pick the right AI tool. It's make the repo so good that it doesn't matter which tool you picked.
Sources:
- Custom instructions with AGENTS.md — OpenAI Codex
- AGENTS.md — the open format, stewarded by the Linux Foundation
- Steering AI Agents in Monorepos with AGENTS.md — Datadog Frontend
- Writing a good CLAUDE.md — HumanLayer
- CLAUDE.md, AGENTS.md & Copilot Instructions — DeployHQ
- I Built the Guardrails Into the Repo, Not the Prompt — DEV Community
- Claude Code Hooks: AI Agent Guardrails — Undercode
- Claude and Codex now available for Copilot Business & Pro — GitHub Changelog