I don't know how long it had been happening before I noticed.
I was running an AI agent through OpenClaw on Telegram — my own setup, handling all sorts of conversations. And one day I looked at a response and thought: this doesn't feel complete. The answer just ended, mid-thought, like someone had pressed stop.
No error. No "message too long" warning. Nothing in the logs. Just a response that stopped early.
I figured it was the model. Bad generation, token limit, something on that end. But it kept happening with long responses, and the cut-off point was weirdly consistent. Always around the same length. And then I started wondering — had previous responses been cut too? Ones I didn't catch because I wasn't paying close enough attention?
That thought bothered me more than the bug itself.
It Wasn't the Model
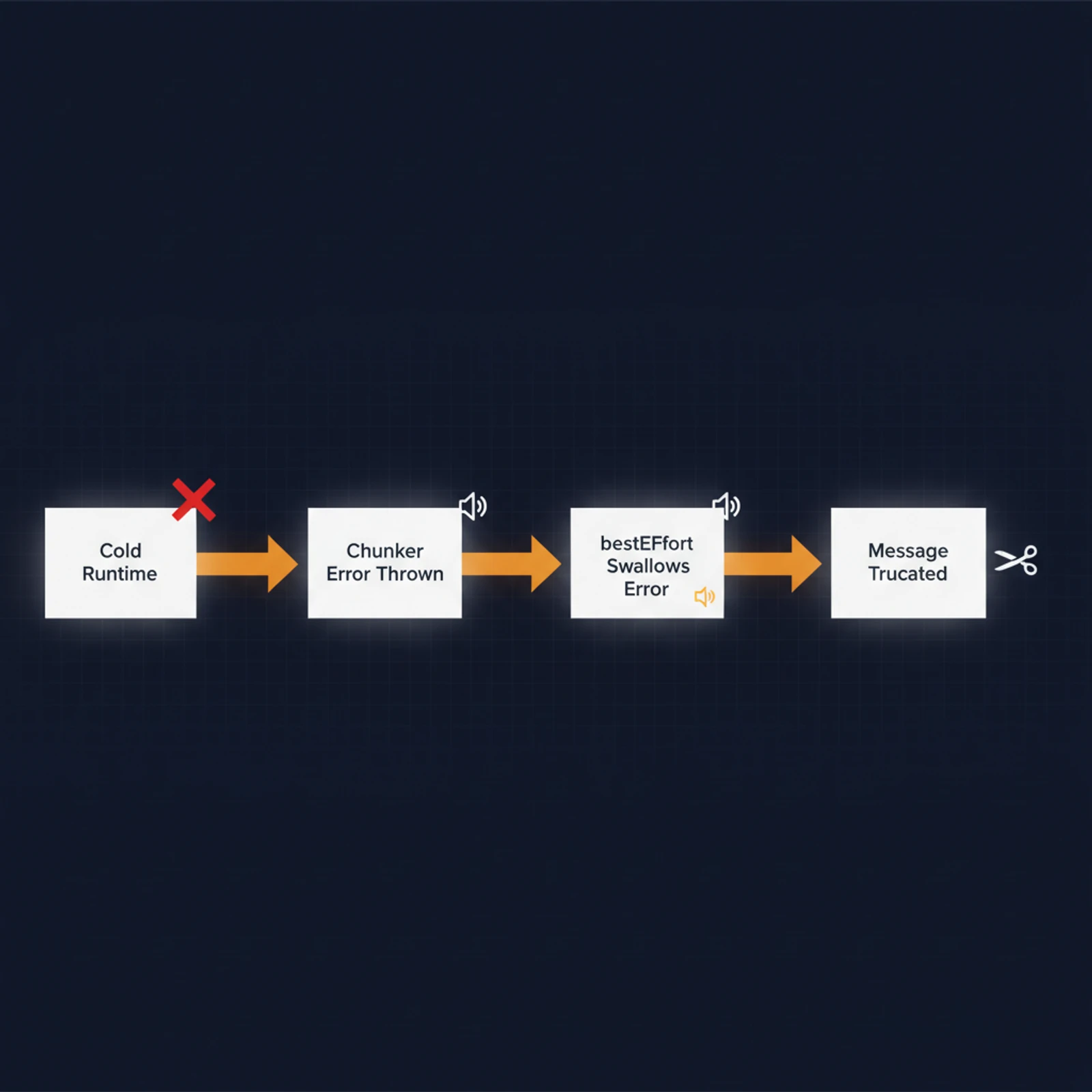
Telegram's Bot API caps messages at 4,096 characters. OpenClaw has always known this — there's a chunker that splits anything longer into multiple messages. A 10,000-character response shows up as three messages in sequence. It had been working fine for months.
I searched the community and found Issue #57746. Other people were hitting the same thing after the v2026.3.13 update. Long messages were no longer getting split. OpenClaw's fallback was silently truncating them to 4,096 characters and sending a single message. Everything past that — gone.
A confirmed regression. Labeled, documented. And sitting there with no one working on it.
The Quiet Kind of Broken
What made this one stick with me is that it's the kind of bug you can live with for weeks without knowing. Your AI gives you a response that seems fine. It's coherent, it makes sense, it just... isn't everything the model actually produced. There's no signal that you're missing something. You'd only catch it if you happened to expect a longer answer and noticed it was short.
Going through the git history, the cause was clear enough. A big refactor — "route channel runtime via plugin api," dozens of files changed — had rewritten the Telegram chunker from a static function call to one that goes through the runtime. Same function at the end of the chain, but now it depended on the Telegram runtime being initialized first. When it's not ready, the call throws. And the delivery pipeline catches that error silently, skips the splitting, and truncates instead.
WhatsApp and Signal were unaffected — their chunkers hadn't been touched. Only Telegram caught the bug.
Going In
I've never contributed to an open source project. I've used them every day for years, but always from the user side. The idea of opening a PR on someone else's codebase felt bigger than it probably should.
But this bug was right there in front of me, it was affecting my daily usage, and the issue tracker had no one on it. At some point the question stopped being "should I try?" and became "how long am I going to keep living with broken messages?"
So I forked the repo and started learning how contributions work. Branch naming, test suites, commit message conventions. I wrote everything down as I went — partly for next time, partly because the process felt less intimidating when I turned it into a checklist.
The actual fix I worked on with Claude. This wasn't reverting a line of code — the refactor had restructured the entire SDK, the old import paths didn't exist anymore. I had to figure out where the chunking function actually lived in the new codebase and which variant to use. There were several — some return HTML, some return markdown. Pick the wrong one and you'd get double-rendering downstream. With Claude I traced through the code, found chunkMarkdownText in the plugin SDK's reply-runtime module, confirmed it matched what the downstream send path expected, and wired it in as a direct import.
+ import { chunkMarkdownText } from "openclaw/plugin-sdk/reply-runtime"
- chunker: (text, limit) => getTelegramRuntime().channel.text.chunkMarkdownText(text, limit),
+ chunker: chunkMarkdownText,Two lines added, one removed. Tests passed. I opened PR #57816 and waited. About a week later, the maintainer merged it.
What Stayed With Me
It's not the PR that I keep thinking about. It's the period before I found the bug, when my agent was quietly giving me incomplete answers and I had no idea. How many times did I read a response, think "that covers it," and move on — not knowing there was more? I'll never know.
This is what silent failures do. They don't crash your system, they don't show you errors. They just degrade things a little, quietly, and you adapt without realizing you're adapting to something broken.
The fix was two lines. The process of getting there — learning to contribute, navigating an unfamiliar codebase with Claude, understanding a refactor I wasn't part of — that's what took the time. But now I have a playbook, and next time the overhead won't be there.
I'm not going to start contributing to open source regularly. But the next time I'm living with a bug that nobody's fixing, I'll probably just fix it.