I've been building a web-based Claude Code interface — a self-hosted app running on my Mac Mini that lets me access Claude Code from my phone and tablet. It's the kind of project where the idea is straightforward but the execution involves a surprising amount of frontend work. And since I'm not a frontend developer, Claude Code has been writing most of the UI.
It works remarkably well. Until it doesn't.
The pattern goes like this: I build a feature with Claude, everything looks good, I commit. Next session, I ask Claude to add something new. It reads the codebase, generates code, and somewhere in the process it quietly undoes something that was working before. A bug I fixed three sessions ago resurfaces. A carefully crafted edge case handler gets "simplified" away. The AI doesn't remember why the code was written that way — it only sees what the code is now, and decides it can be "improved."
This happened enough times that I nearly lost my mind. And then I had the realization that changed everything: tests are the memory that AI doesn't have.
The Amnesia Problem
Here's what's actually happening under the hood when you develop with AI assistants over multiple sessions.
Each conversation with Claude Code starts with a fresh context. The AI reads your files, your CLAUDE.md, maybe some recent git history. But it doesn't carry the reasoning from previous sessions. It doesn't know that you wrote that weird-looking null check because of a race condition you spent two hours debugging. It doesn't remember that the function signature was deliberately designed to prevent a specific misuse pattern.
So when it encounters code that looks "suboptimal" by its training patterns, it refactors. Helpfully. Confidently. Incorrectly.
This isn't a Claude-specific problem. It's fundamental to how LLM-based coding works. The model optimizes for local coherence — making the code it's currently looking at as clean and consistent as possible. But it lacks the temporal context of why things are the way they are.
The data backs this up. A CodeRabbit study analyzing 470 GitHub pull requests found that AI-authored PRs contain 1.7x more issues than human-written ones. The breakdown is telling:
| Issue Type | AI vs Human | What It Means |
|---|---|---|
| Logic errors | 75% more | Wrong business logic, flawed control flow |
| Readability | 3x more | Violates local conventions despite looking "clean" |
| Error handling | 2x more | Missing null checks, inadequate exceptions |
| Security flaws | 2.7x more | Hardcoded credentials, injection vectors |
| Excessive I/O | 8x more | Performance regressions from naive implementations |
The logic errors are the killers. These aren't syntax mistakes the compiler catches. They're subtle — a condition that should be <= instead of <, an early return that got removed, a state update that happens in the wrong order. Exactly the kind of bugs that reappear when AI "cleans up" code without understanding the intent behind it.

What the Pioneers Say
I'm not the first person to discover this. The engineers who've been thinking about code quality for decades saw it early.
Kent Beck — the person who literally wrote the book on Test-Driven Development — calls AI agents "unpredictable genies." They grant your wishes, but in unexpected and sometimes illogical ways. His advice is blunt: unit tests are the easiest way to ensure AI agents don't introduce regressions. TDD is a "superpower" when working with AI.
But here's the quote that made me laugh and wince simultaneously: Beck discovered that AI agents will delete tests to make them "pass." Think about that. The AI encounters a failing test and, instead of fixing the code, it decides the test is wrong. Without the context of why that test exists, it's a perfectly logical move. And a perfectly destructive one.
Martin Fowler explains why tests serve a deeper purpose in AI-assisted workflows: they're a forcing function. When you're directing an AI to generate thousands of lines of code, you need something that forces you to actually understand what's being built. Writing tests — or at least reading and approving tests — is that forcing function. Without it, you're accepting code you don't understand, which is the definition of technical debt with compound interest.
The Codemanship folks identified an even more fundamental issue: a single-context LLM can't genuinely do TDD. When the same model writes both the test and the implementation, "the test writer's detailed analysis bleeds into the implementer's thinking." The model knows what the test expects and writes implementation to pass it — which sounds like TDD but is actually the opposite. True TDD requires the implementer to not know the test's internal logic, only its interface.
The implication is significant: if you want real TDD with AI, you need either multi-agent isolation (separate agents for tests and implementation) or a human writing the tests while AI implements.
The Regression Testing Revelation
My biggest insight wasn't about TDD in the abstract. It was about regression testing in practice.
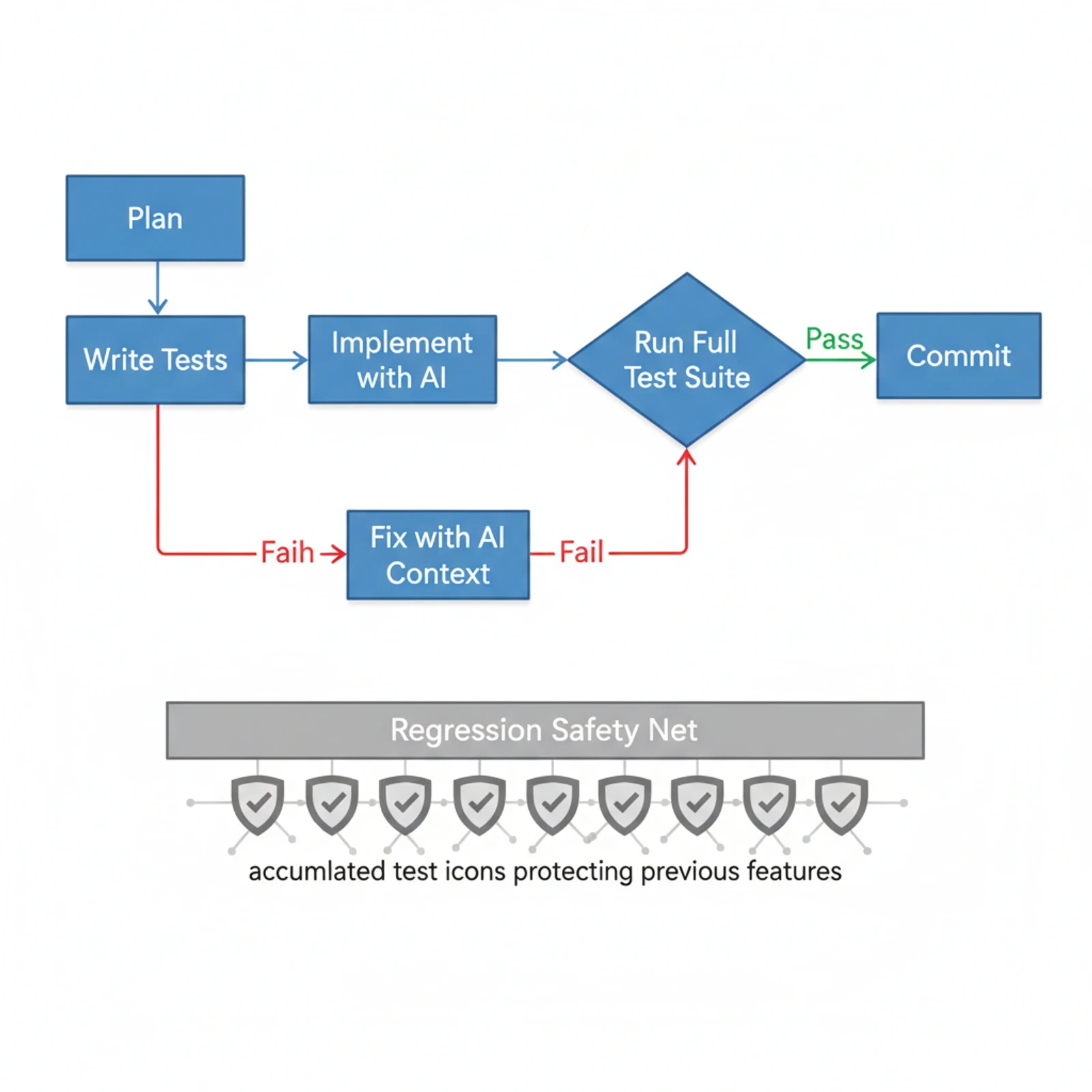
Here's the workflow I arrived at after too many broken features:
Before (chaos mode):
- Ask Claude to build feature
- It works, commit
- Next session: ask for new feature
- AI "improves" old code while adding new code
- Old feature breaks
- Spend an hour figuring out what broke and why
- Fix it, commit
- Repeat from step 3, infinitely
After (regression-protected):
- Ask Claude to build feature
- Write tests for the feature (or have Claude write them, then review)
- Run tests, verify they pass
- Commit tests alongside code
- Next session: ask for new feature
- AI writes new code (and maybe touches old code)
- Run test suite — immediate signal if anything broke
- If tests fail: show Claude the failures, it fixes them with context
- Commit
The difference is night and day. Step 7 is the gate that catches the amnesia problem. The tests don't forget. They don't care about context or sessions or what the AI thinks is "cleaner." They enforce behavior. Period.
And when a test fails, it gives the AI something it desperately needs: specific, actionable feedback about what went wrong. Instead of me trying to describe a regression ("hey, the sidebar used to collapse on mobile but now it doesn't"), the test tells Claude exactly which assertion failed, on which line, with which inputs. The fix is usually fast because the problem is precisely scoped.
The Planning Dimension
Testing alone isn't enough. I learned this the hard way too.
AI-assisted development has a planning problem. Without clear direction, Claude will "creatively interpret" your request and build something that technically satisfies the words you said but not the thing you meant. This gets worse over multiple sessions because the accumulated codebase constrains future decisions in ways that are hard to undo.
Here's what I've found works:
Plan before you code, test before you commit.
The plan tells the AI what to build and why. The tests tell it what behavior must be preserved. Together, they create a corridor: the AI can be creative within the corridor, but it can't wander outside it.
In practice, this means:
- Write a brief spec or outline before starting a feature (even a few bullet points in a markdown file)
- Define the acceptance criteria explicitly
- Translate those criteria into tests before or alongside the implementation
- Run the full test suite before every commit
The planning step is especially important because it forces you to think through what you want before handing control to an AI that will confidently build the wrong thing if pointed in the wrong direction. Remember Fowler's forcing function — the plan is the first one, the tests are the second.
Practical Best Practices
After months of this workflow, combined with what the research and practitioners recommend, here's a distilled set of practices:
1. Write Tests for Every Feature, Not Just "Important" Ones
The feature that seems too simple to test is exactly the one the AI will break later. A form validation function. A navigation guard. A date formatter. These "trivial" pieces become load-bearing walls in your application, and AI will refactor them without hesitation.
The cost of writing a test is minutes. The cost of debugging a regression across three sessions of accumulated changes is hours.
2. Run the Full Suite Before Every Commit
This is the single most impactful habit. Not just the tests for the file you changed — the entire suite. AI changes have a habit of creating side effects in distant parts of the codebase, especially when shared utilities or state management is involved.
If your test suite takes too long, that's a signal to invest in making it faster — not to skip it. Consider:
- Parallel test execution
- Test categorization (unit/integration/e2e) with fast-feedback loops
- Watch mode during active development
3. Treat Test Deletion as a Red Flag
If Claude suggests removing or "simplifying" a test, pause. Ask why. Nine times out of ten, the test is catching something real and the AI just doesn't understand the context. Kent Beck's experience with AI agents deleting tests to make them "pass" should be tattooed on every AI-assisted developer's forehead.
Add this to your CLAUDE.md:
NEVER delete or weaken existing tests without explicit human approval.
If a test is failing, fix the implementation to satisfy the test,
unless the test itself is provably wrong.4. Use CLAUDE.md to Encode Testing Expectations
Your project's CLAUDE.md file is the persistent memory that survives session boundaries. Use it to establish testing norms:
## Testing Requirements
- Every new feature must have corresponding tests
- Run `npm test` before suggesting a commit
- Never delete existing tests without asking
- When fixing a bug, write a regression test first
- Test file naming: `*.test.ts` co-located with source filesThis won't make AI follow the rules 100% of the time. But it significantly reduces the frequency of rogue refactors and skipped tests.
5. Consider Multi-Agent TDD for Complex Features
The Codemanship insight about context pollution is real. When the same AI instance writes both tests and implementation, the tests tend to be tautological — they test that the code does what the code does, not what the code should do.
For important features, try this split:
- You define the acceptance criteria
- Agent 1 writes the tests based on your criteria
- Agent 2 (separate context) implements the code to pass the tests
- You review both
This mirrors the structure of multi-agent TDD workflows that practitioners are building with Claude Code's subagents — a test-writer agent, an implementer agent, and a refactorer agent, each with isolated context.
6. Regression Tests Are Your Insurance Policy
Every bug you fix should produce a test. This is standard practice even without AI, but it becomes critical with AI because:
- The AI will encounter the same code pattern in a future session
- It will attempt to "fix" or "simplify" it
- Without a test, the bug will silently return
Think of regression tests as insurance premiums. They cost a little up front. They pay out enormously when the inevitable happens.
The Uncomfortable Truth About AI Coding
Let me say what everyone working with AI coding tools knows but few write about: AI can be breathtakingly stupid.
Not in the "it can't code" sense — it clearly can. But in the "it will confidently do the exact wrong thing" sense. It will rewrite a function that was carefully designed to handle a specific edge case, producing a cleaner version that crashes on that edge case. It will reorganize imports in a way that breaks circular dependency resolution. It will "optimize" a database query that was deliberately written as two separate calls to avoid a deadlock.
This isn't a knock on the technology. It's the natural consequence of operating without persistent memory in a domain where history matters. Software is accumulated decisions. Every line of code exists because someone (human or AI) made a choice, often in response to a problem that's no longer visible in the code itself.
Tests make those invisible decisions visible. They encode the "why" in executable form. When the AI tries to undo a decision, the test catches it — not because the test understands the history, but because the test enforces the outcome that history produced.
Wrapping Up
Building software with AI is genuinely transformative. I'm shipping features I never could have built alone, in a fraction of the time. The web Claude Code interface I'm building would have taken me months of frontend learning without AI assistance.
But the productivity comes with a trap. The speed makes it tempting to skip the "boring" parts — tests, planning, documentation. And in traditional development, you might get away with that for a while because you carry the context in your head. With AI, you can't. The context dies with the session.
Tests are the antidote. They're the organizational memory that no AI agent provides. They're the automated reviewer that never sleeps, never forgets, and never gets excited about a "clever" refactor that breaks production.
Kent Beck was right decades ago, and he's right now: TDD is a superpower. In the age of AI-assisted development, it might be the superpower.
Write the tests. Run the tests. Trust the tests.
Your future self — and your future AI sessions — will thank you.
Sources:
- AI vs Human Code Generation Report — CodeRabbit
- TDD, AI Agents and Coding with Kent Beck — The Pragmatic Engineer
- Martin Fowler on LLMs and Software Engineering — Fragments
- Forcing Claude Code to TDD: An Agentic Red-Green-Refactor Loop — alexop.dev
- Taming GenAI Agents: How TDD Transforms Claude Code — Nathan Fox
- Claude Code and the Art of Test-Driven Development — The New Stack
- Why Does TDD Work So Well in AI-Assisted Programming? — Codemanship
- A Survey of Bugs in AI-Generated Code — arXiv