This article provides a comprehensive analysis of two Databricks modes: traditional Notebook mode and Delta Live Tables (DLT). It aims to guide you in selecting the mode best suited for your company's needs by examining the pros and cons of each, outlining suitable use cases, and considering other crucial factors beyond the initial requirements.
Databricks Notebook Mode
Databricks Notebooks offer an interactive environment for developing and executing code, visualizing data, and collaborating with colleagues. They are widely used for data exploration, analysis, and machine learning workflows. Notebooks are a popular way to begin working with data quickly without the need to configure a complex environment. They simplify continuous integration and deployment by allowing tests to run against the latest pull request and enabling jobs to pull the latest release from version control.
Pros of Notebook Mode
- Interactive and Collaborative: Notebooks provide a user-friendly interface for writing, executing, and visualizing code in multiple languages (Python, SQL, Scala, R). Real-time co-authoring features facilitate seamless collaboration among team members.
- Versatile and Flexible: Notebooks support a wide range of tasks, from ad-hoc analysis and data exploration to developing complex machine learning models. They allow for easy integration with various data sources and libraries.
- Reproducible Workflows: The cell-based structure enables step-by-step execution and documentation of the entire data analysis process, ensuring reproducibility.
- Scalability: Notebooks can be attached to clusters with varying compute resources to handle different workloads.
- Automation: Databricks notebooks can easily be automated using the Databricks jobs feature. You can schedule your notebooks to run periodically or trigger them on demand or by events.
- Version Control: Databricks Notebooks automatically track changes, allowing for easy rollback to previous versions. Git integration enables efficient code management and collaboration.
- Debugging Capabilities: Databricks Notebooks offer debugging tools to identify and resolve code errors, streamlining the development process.
- Simplified Environment: Notebooks provide a ready-to-use environment for data analysis, eliminating the need for complex setup and configuration.
Cons of Notebook Mode
- Cost Considerations: Using All-Purpose Clusters for production workloads in Notebook mode can be expensive.
- Potential for Development Challenges: Notebooks may encourage less structured development practices compared to traditional software development approaches.
- Limitations with Serverless Compute: Notebooks running on serverless compute have memory limitations and lack support for certain features like notebook-scoped libraries caching and sharing TEMP tables.
- Debugger Limitations: The debugger currently only supports Python and has limitations with Shared access mode clusters and external files.
- ipywidgets Limitations: Notebooks using ipywidgets have limitations related to state preservation, unsupported widgets, rendering issues in dark mode, and dashboard views.
Databricks Delta Live Tables (DLT)
DLT is a declarative framework in Databricks for building reliable, maintainable, and testable data processing pipelines. It simplifies ETL development by allowing you to define your pipeline declaratively, automating orchestration, cluster management, monitoring, and data quality. With DLT, you can build pipelines using SQL or Python, specify incremental or complete computation, and reuse pipelines across different environments.
Pros of DLT Mode
- Simplified ETL Development: DLT allows you to define pipelines declaratively, focusing on the desired outcome rather than the intricate steps.
- Automated Operations: DLT automates various operational aspects, including task orchestration, cluster management, monitoring, and data quality enforcement.
- Cost Optimization: DLT optimizes pipeline execution for cost-efficiency, potentially achieving significant cost reductions compared to traditional approaches (nearly 4x Databricks baseline).
- Performance Optimization: DLT leverages the performance advantages of Delta Lake, enabling efficient handling of large datasets and fast query execution.
- Streamlined Medallion Architecture: DLT facilitates the implementation of a streamlined medallion architecture with streaming tables and materialized views.
- Data Quality Control: DLT provides built-in features like expectations to ensure data quality and prevent bad data from propagating through the pipeline.
- Support for Batch and Streaming: DLT supports both batch and streaming data processing, providing a unified approach for different data velocities.
- Change Data Capture (CDC): DLT supports CDC, enabling efficient capture and processing of continuously arriving data.
- Enhanced Auto Scaling: DLT offers enhanced auto-scaling capabilities for improved performance, particularly with streaming workloads.
- Development and Production Modes: DLT supports both development and production modes, allowing you to test and iterate on your pipelines in a controlled environment before deploying them to production.
- Pipeline Visibility and Management: DLT provides comprehensive visibility into pipeline operations, including metrics, logs, and lineage information, making it easier to monitor and manage data pipelines.
- IDE Support: You can develop DLT pipelines in an IDE locally or in Databricks Notebooks, providing flexibility in development environments.
- Delta Live Event Monitoring: DLT offers Delta Live Event Monitoring, which tracks events and provides insights into pipeline operations.
- Data Freshness Control: DLT allows you to refresh pipelines in continuous or triggered mode to fit your data freshness needs.
- Reusability of Pipelines: DLT pipelines can be reused across different environments and use cases, promoting modularity and efficiency.
Cons of DLT Mode
- Schema Limitations: All tables within a DLT pipeline must adhere to the same schema.
- Limited Pipeline Control: DLT lacks flexibility in pipeline control, which can be challenging for complex scenarios.
- Troubleshooting Challenges: Debugging and troubleshooting DLT pipelines can be complex.
- Limited Support for Third-Party Libraries: DLT has limited support for third-party libraries, potentially restricting functionality.
- Challenges with Unity Catalog: DLT faces limitations when used with Unity Catalog, particularly with the medallion architecture and third-party library support.
- CDC Limitations: DLT's CDC capabilities have limitations, particularly with delete operations and merge operations for Delta tables.
- Constraints on Table Definitions and Writes: DLT has limitations on defining tables multiple times and concurrent writes to tables.
- Data Validation Limitations: DLT's data validation capabilities are limited compared to other tools.
- Manual Deletes and Updates: For most operations, DLT should handle all updates, inserts, and deletes to a target table. However, there are limitations to retaining manual deletes or updates.
Suitable Use Cases
Notebook Mode
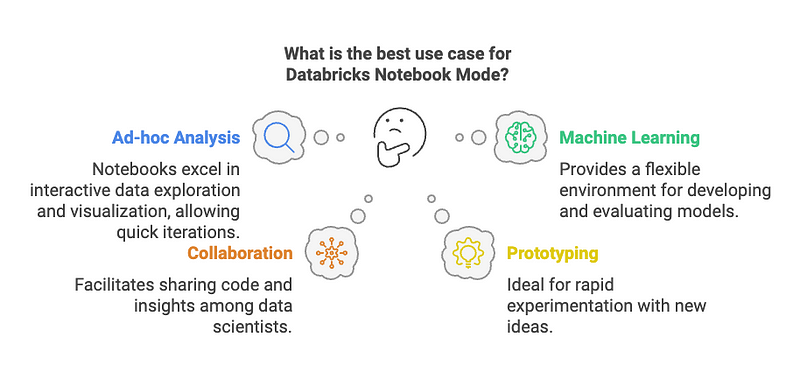
- Ad-hoc analysis and data exploration: Notebooks excel in interactive data exploration and analysis, allowing users to quickly iterate and visualize data.
- Machine learning model development: Notebooks provide a flexible environment for developing, training, and evaluating machine learning models.
- Collaborative data science projects: Notebooks facilitate collaboration among data scientists, enabling them to share code, visualizations, and insights.
- Prototyping and experimentation: Notebooks are ideal for rapid prototyping and experimentation with new ideas and techniques.
- Creating dashboards and visualizations: Notebooks can be used to create interactive dashboards and visualizations to communicate data insights.
DLT Mode
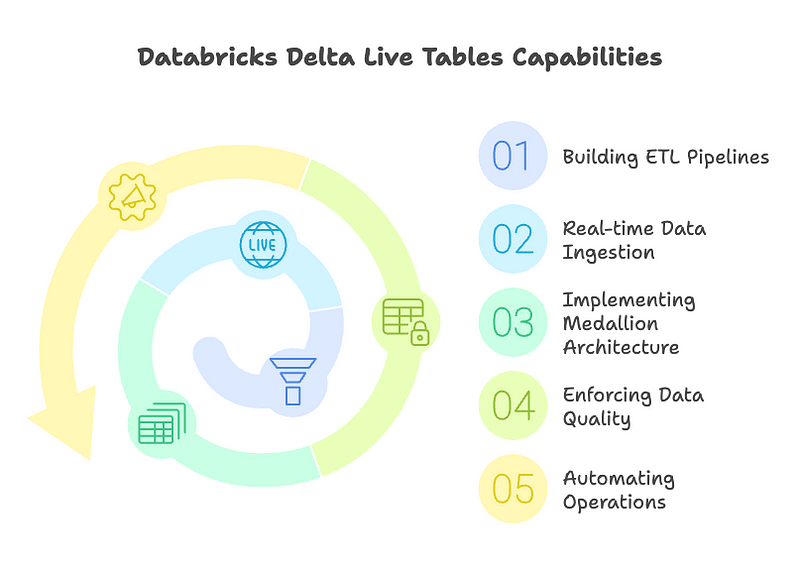
- Building production-ready ETL pipelines: DLT simplifies the development and deployment of reliable and maintainable ETL pipelines.
- Real-time data ingestion and processing: DLT is well-suited for ingesting and processing streaming data, enabling real-time analytics and applications.
- Implementing a streamlined medallion architecture: DLT facilitates the implementation of a robust and scalable medallion architecture for data lakehouses.
- Enforcing data quality and consistency: DLT provides built-in mechanisms to ensure data quality and prevent bad data from impacting downstream processes.
- Automating data pipeline operations: DLT automates various operational aspects, reducing manual effort and improving efficiency.
Examples
Notebook Mode
- A data scientist uses a notebook to explore a new dataset, visualize patterns, and build a machine learning model to predict customer churn. The interactive nature of notebooks allows for rapid iteration and experimentation with different model parameters and features.
- A data engineer uses a notebook to prototype a new data pipeline, test different transformations, and visualize the results. The notebook provides a flexible environment to experiment with various data sources, transformations, and output formats before implementing the pipeline in a production environment.
- A business analyst uses a notebook to create an interactive dashboard to track key performance indicators and share insights with stakeholders. The notebook allows for embedding visualizations and interactive controls to create a dynamic and engaging dashboard.
DLT Mode
- A company uses DLT to build a real-time data pipeline that ingests sensor data from IoT devices, performs transformations, and stores the results in a Delta Lake table for analysis. DLT's support for streaming data and automated operations ensures that the data is processed in real-time and with high reliability.
- An e-commerce company uses DLT to create a pipeline that captures changes in customer orders, updates inventory levels, and generates real-time reports on sales performance. DLT's CDC capabilities and support for real-time data processing enable the company to maintain up-to-date inventory information and track sales performance with minimal latency.
- A financial institution uses DLT to build a data pipeline that ingests transaction data, performs fraud detection analysis, and generates alerts for suspicious activities. DLT's data quality features and automated operations ensure the accuracy and reliability of the fraud detection process.