As a data architect, I’m always on the lookout for innovative ways to extract value from unstructured data. Recently, I explored the idea of integrating Retrieval-Augmented Generation (RAG) agents into a workflow for querying PDFs and web data. The results? Promising, yet not without challenges. Let me walk you through the journey, the tech stack, the outcomes, and the lessons learned along the way.
The Goal: Enhancing Response Quality
The primary objective of this experiment was straightforward: to see if leveraging agents in a RAG setup could improve the quality of responses when querying PDFs and web-based information. Spoiler alert: it worked. But, as with any innovation, the path wasn’t all smooth sailing.
The Tech Stack: What Powered the Experiment
For the frontend, I chose Streamlit to provide an interactive interface where users could upload PDFs or ask questions. Streamlit was great for quick prototyping and testing, offering a user-friendly experience.
On the backend, I employed CrewAI, a framework to orchestrate tasks among agents and tools. CrewAI was responsible for creating and managing agents like:
- PDFTool: To parse and index uploaded PDFs.
- WebSearchTool: For retrieving supplementary information from the web when needed.
- RetrieverAgent: Powered by Azure OpenAI (GPT-4), this agent fetched relevant data from indexed PDFs.
- SynthesizerAgent: Also GPT-4-powered, this agent synthesized the retrieved information into coherent, contextually relevant responses.
To improve the PDF chunk indexing and optimize overall performance, we integrated Qdrant, a vector database. By storing PDF chunks as vector embeddings, Qdrant allowed for more efficient and accurate retrieval. Additionally, we kept all operations in memory, which significantly enhanced speed and minimized latency.
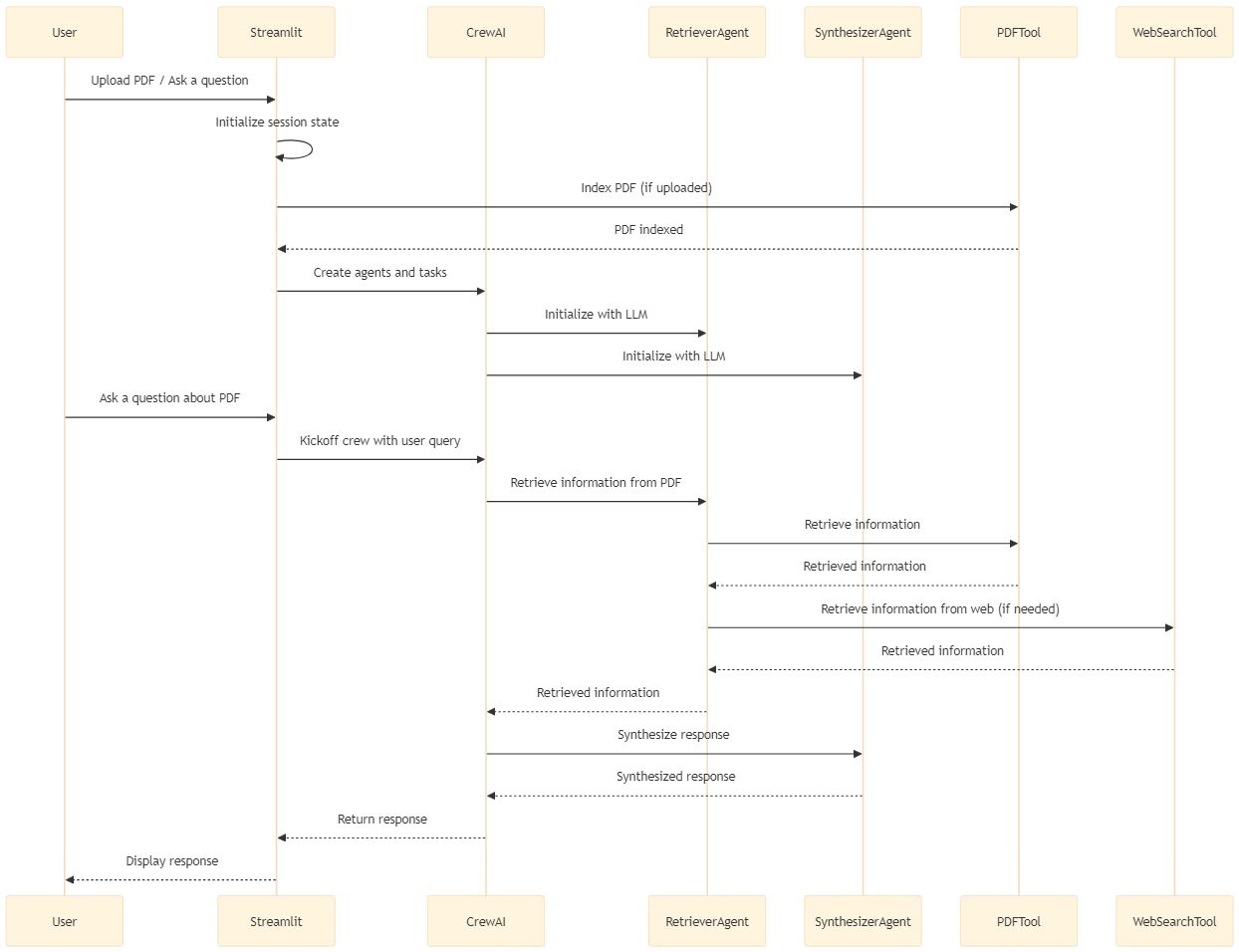
How It Worked: The Workflow
- Uploading and Initialization: Users uploaded a PDF or directly asked a question. The session initialized by indexing the PDF if uploaded.
- Query Processing: The user’s query triggered CrewAI to activate agents.
- The RetrieverAgent pulled relevant data from the PDF or web.
- If web data was required, the WebSearchTool stepped in.
- Response Synthesis: The SynthesizerAgent combined all retrieved information into a polished response.
- Results Display: The final response was presented via Streamlit.
The Outcomes: Highs and Lows
The Highs:
- Improved Response Quality: Using RAG agents significantly boosted the contextual relevance and depth of responses. The ability to synthesize data from PDFs and web sources was a significant improvement.
- Scalability: The modular setup allowed for easy integration of additional tools or agents as needed.
- Performance Gains: Leveraging Qdrant for vector-based indexing and keeping operations in memory resulted in faster and more efficient processing.
The Challenges:
- Performance Bottlenecks: Orchestrating multiple agents and tools still introduced latency in complex scenarios.
- Operational Costs: The intensive use of GPT-4o APIs quickly escalated costs. To address this, we are considering alternatives like DeepSeek R1, which offers good LLM capabilities at a lower cost, making it a promising option for cost reduction and efficient performance.
The Road Ahead: Optimizing for the Future
While the initial results were encouraging, there’s room for improvement. Here’s what’s next:
-
Performance Enhancements:
- Further optimizing vector searches in Qdrant.
- Implementing additional caching mechanisms to reduce redundant queries.
- Exploring parallel processing to speed up agent interactions.
- Evaluating good ROI LLM models like DeepSeek R1 or V3 for cost-effective and efficient performance improvements.
-
Cost Management:
- Allocating resources more effectively by balancing API usage with response quality.
- Experimenting with alternative models or fine-tuned versions for specific tasks.
-
User Experience:
- Moving beyond Streamlit for production-grade interfaces that are more robust and visually appealing.
- Offering customization options for users to fine-tune queries and responses.
Final Thoughts
This experiment reaffirmed the potential of RAG agents in tackling unstructured data challenges. The combination of advanced LLMs, vector databases like Qdrant, and specialized tools offers a powerful approach to extracting insights, but it comes with its trade-offs in terms of speed and cost.
For anyone venturing into similar territory, my advice is simple: Start small, measure impact, and iterate. And don’t forget to enjoy the process—because when data starts making sense in ways you never thought possible, it’s a rewarding experience.
So, what’s your take on using agents for RAG? Let’s discuss!